Shuffling large data at constant memory in Dask
By Hendrik Makait
This work was engineered and supported by Coiled. In particular, thanks to Florian Jetter, Gabe Joseph, Hendrik Makait, and Matt Rocklin. Original version of this post appears on blog.coiled.io
With release 2023.2.1, dask.dataframe introduces a new shuffling method called P2P, making sorts, merges, and joins faster and using constant memory.
Benchmarks show impressive improvements:
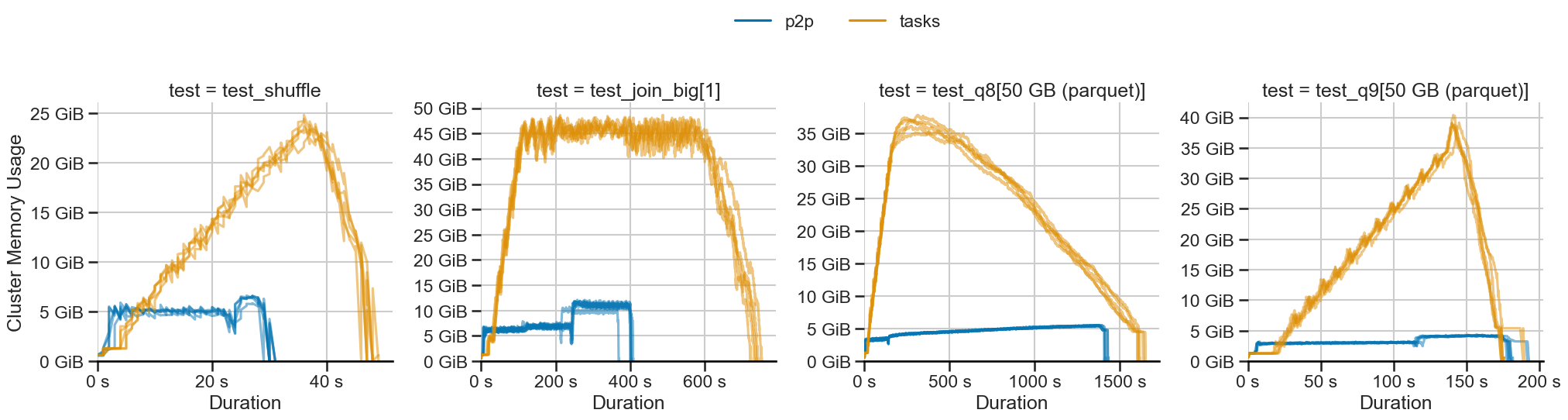
P2P shuffling (blue) uses constant memory while task-based shuffling (orange) scales linearly.
This article describes the problem, the new solution, and the impact on performance.
What is Shuffling?
Shuffling is a key primitive in data processing systems. It is used whenever we move a dataset around in an all-to-all fashion, such as occurs in sorting, dataframe joins, or array rechunking. Shuffling is a challenging computation to run efficiently, with lots of small tasks sharding the data.
Task-based shuffling scales poorly
While systems like distributed databases and Apache Spark use a dedicated shuffle service to move data around the cluster, Dask builds on task-based scheduling. Task-based systems are more flexible for general-purpose parallel computing but less suitable for all-to-all shuffling. This results in three main issues:
- Scheduler strain: The scheduler hangs due to the sheer amount of tasks required for shuffling.
- Full dataset materialization: Workers materialize the entire dataset causing the cluster to run out of memory.
- Many small operations: Intermediate tasks are too small and bring down hardware performance.
Together, these issues make large-scale shuffles inefficient, causing users to over-provision clusters. Fortunately, we can design a system to address these concerns. Early work on this started back in 2021 and has now matured into the P2P shuffling system:
P2P shuffling
With release 2023.2.1, Dask introduces a new shuffle method called P2P, making sorts, merges, and joins run faster and in constant memory.
This system is designed with three aspects, mirroring the problems listed above:
-
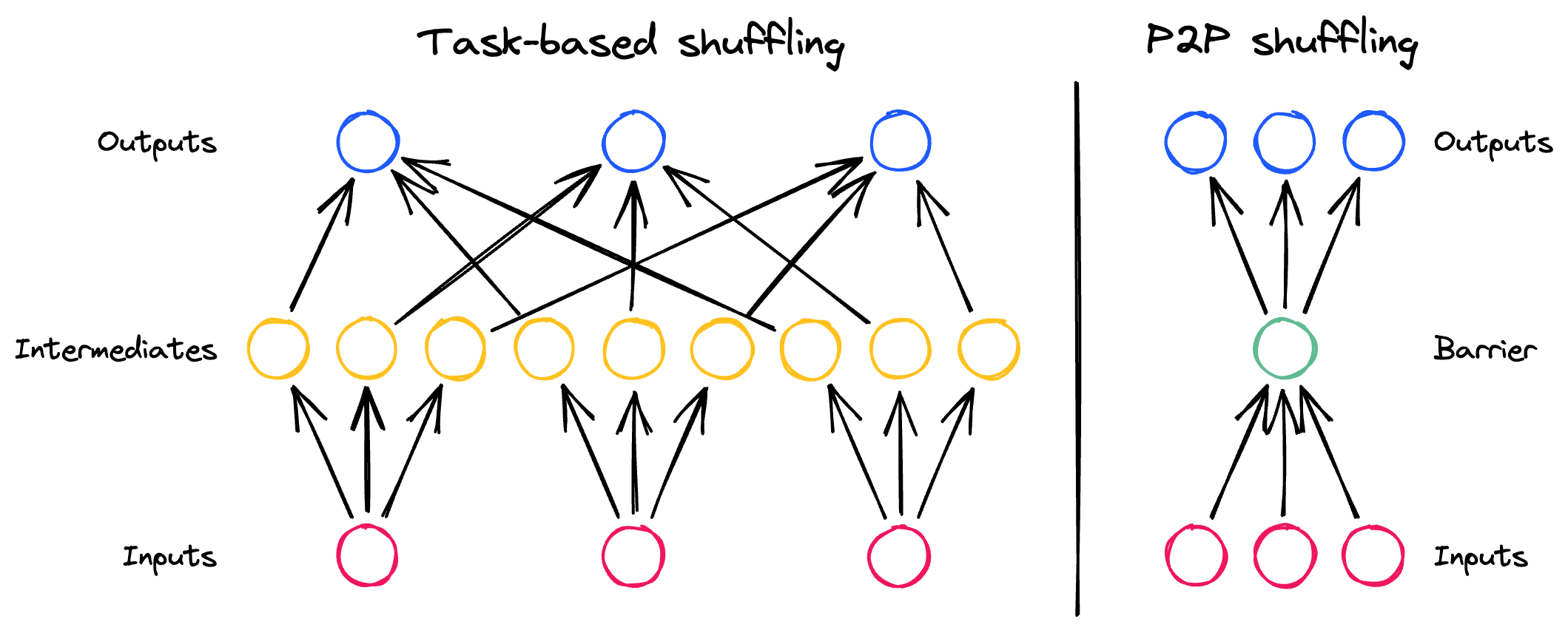
Peer-to-Peer communication: Reduce the involvement of the scheduler
Shuffling becomes an O(n) operation from the scheduler’s perspective, removing a key bottleneck.
-
Disk by default: Store data as it arrives on disk, efficiently.
Dask can now shuffle datasets of arbitrary size in small memory, reducing the need to fiddle with right-sizing clusters.
-
Buffer network and disk with memory: Avoid many small writes by buffering sensitive hardware with in-memory stores.
Shuffling involves CPU, network, and disk, each of which brings its own bottlenecks when dealing with many small pieces of data. We use memory judiciously to trade off between these bottlenecks, balancing network and disk I/O to maximize the overall throughput.
In addition to these three aspects, P2P shuffling implements many minor optimizations to improve performance, and it relies on pyarrow>=7.0 for efficient data handling and (de)serialization.
Results
To evaluate P2P shuffling, we benchmark against task-based shuffling on common workloads from our benchmark suite. For more information on this benchmark suite, see the GitHub repository or the latest test results.
Memory stability
The biggest benefit of P2P shuffling is constant memory usage. Memory usage drops and stays constant across all workloads:
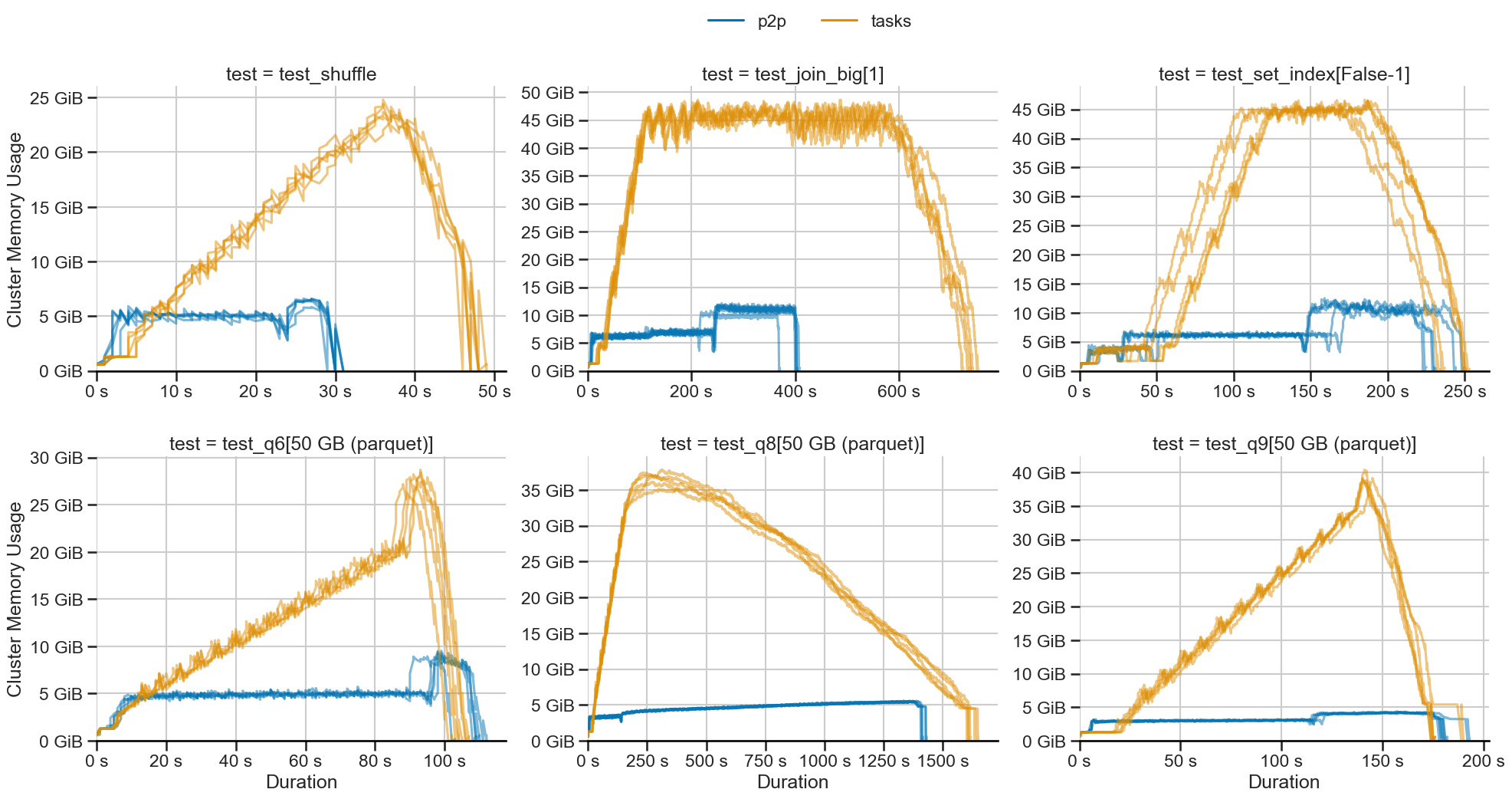
P2P shuffling (blue) uses constant memory while task-based shuffling (orange) scales linearly.
For the tested workloads, we saw up to 10x lower memory. For even larger workloads, this gap only increases.
Performance and Speed
In the above plot, we can two performance improvements:
- Faster execution: Workloads run up to 45% faster.
- Quicker startup: Smaller graphs mean P2P shuffling starts sooner.
Comparing scheduler dashboards for P2P and task-based shuffling side-by-side helps to understand what causes these performance gains:
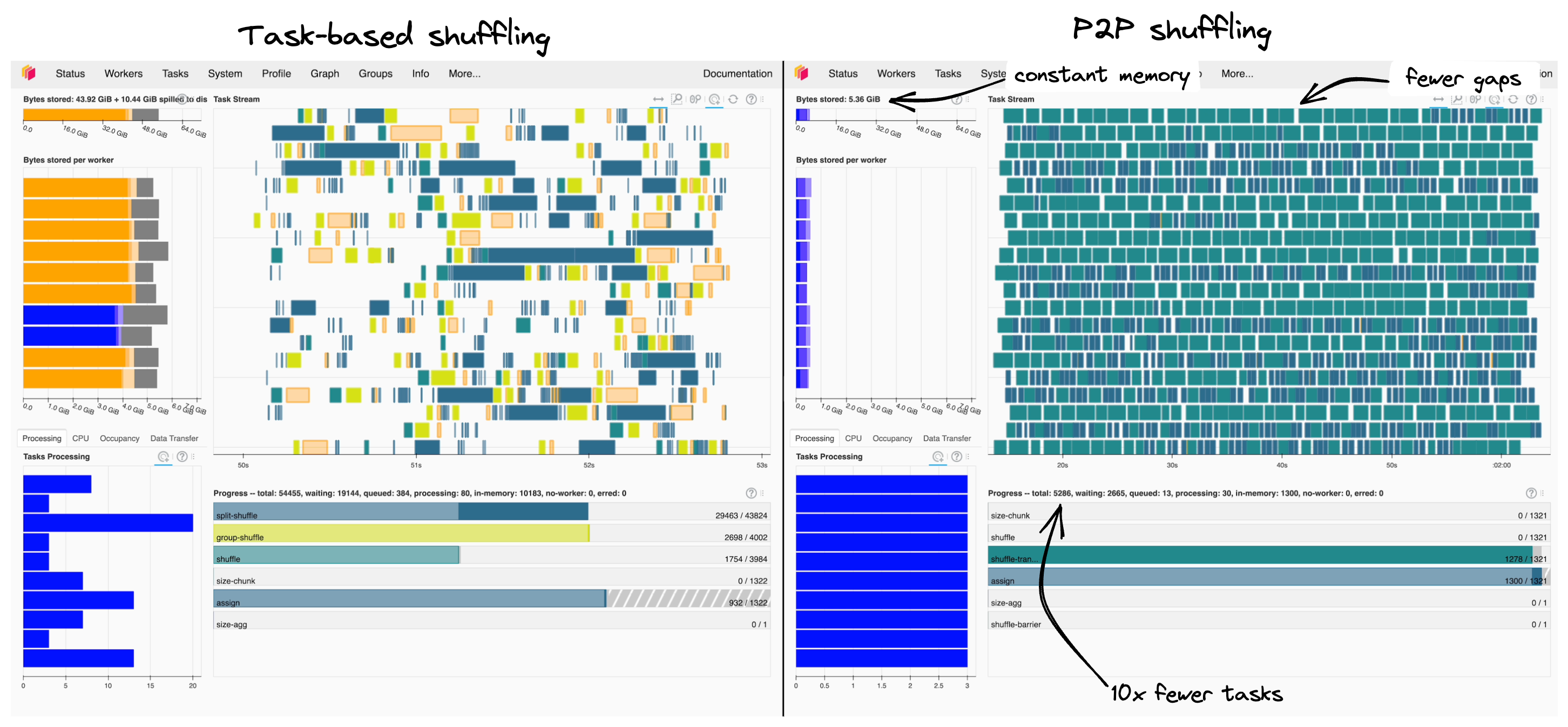
Task-based shuffling (left) shows bigger gaps in the task stream and spilling compared to P2P shuffling (right).
- Graph size: 10x fewer tasks are faster to deploy and easier on the scheduler.
- Controlled I/O: P2P shuffling handles I/O explicitly, which avoids less performant spilling by Dask.
- Fewer interruptions: I/O is well balanced, so we see fewer gaps in work in the task stream.
Overall, P2P shuffling leverages our hardware far more effectively.
Changing defaults
These results benefit most users, so P2P shuffling is now the default starting from release 2023.2.1,
as long as pyarrow>=7.0.0 is installed. Dataframe operations like the following will benefit:
df.set_index(...)df.merge(...)df.groupby(...).apply(...)
Share your experience
To understand how P2P performs on the vast range of workloads out there in the wild, and to ensure that making it the default was the right choice, we would love to learn about your experiences running it. We have opened a discussion issue on GitHub for feedback on this change. Please let us know how it helps (or doesn’t).
Keep old behavior
If P2P shuffling does not work for you, you can deactivate it by setting the dataframe.shuffle.method config value to "tasks" or explicitly setting a keyword argument, for example:
with the yaml config
dataframe:
shuffle:
method: tasks
or when using a cluster manager
import dask
from dask.distributed import LocalCluster
# The dataframe.shuffle.method config is available since 2023.3.1
with dask.config.set({"dataframe.shuffle.method": "tasks"}):
cluster = LocalCluster(...) # many cluster managers send current dask config automatically
For more information on deactivating P2P shuffle, see the discussion #7509.
What about arrays?
While the original motivation was to optimize large-scale dataframe joins, the P2P system is useful for all problems requiring lots of communication between tasks. For array workloads, this often occurs when rechunking data, such as when organizing a matrix by rows when it was stored by columns. Similar to dataframe joins, array rechunking has been inefficient in the past, which has become such a problem that the array community built specialized tools like rechunker to avoid it entirely.
There is a naive implementation of array rechunking using the P2P system available for experimental use. Benchmarking this implementation shows mixed results:
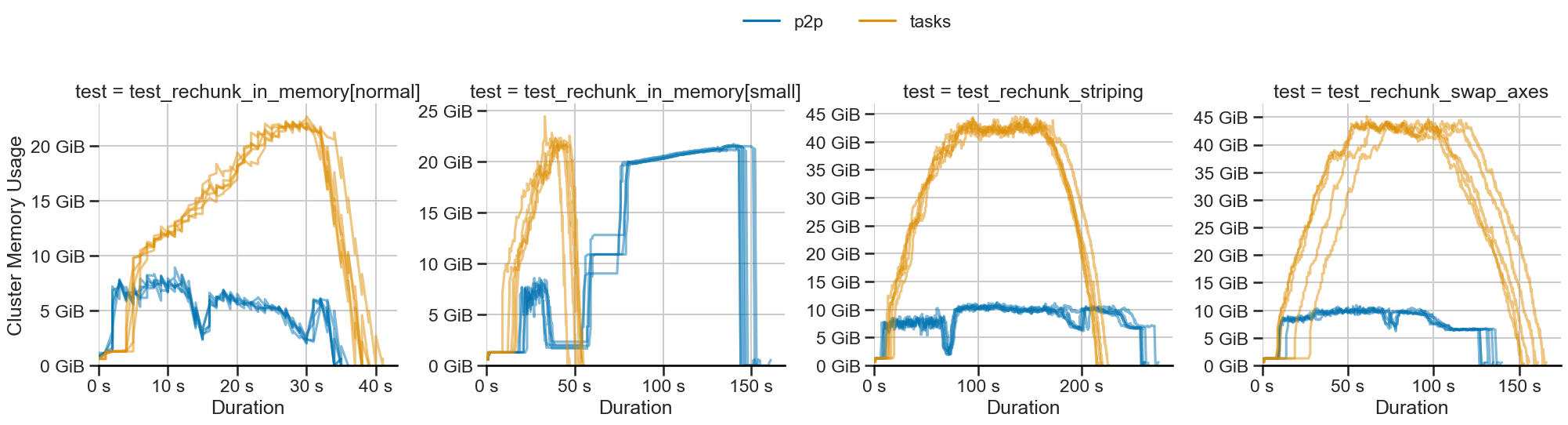
- 👍 Constant memory use: As with dataframe operations, memory use is constant.
- ❓ Variable runtime: The runtime of workloads may increase with P2P.
- 👎 Memory overhead: There is a large memory overhead for many small partitions.
The constant memory use is a very promising result. There are several ways to tackle the current limitations. We expect this to improve as we work with collaborators from the array computing community.
Next steps
Development on P2P shuffling is not done yet. For the future we plan the following:
-
dask.array:While the early prototype of array rechunking is promising, it’s not there yet. We plan to do the following:
- Intelligently select which algorithm to use (task-based rechunking is better sometimes)
- Work with collaborators on rechunking to improve performance
- Seek out other use cases, like
map_overlap, where this might be helpful
-
Failure recovery:
Make P2P shuffling resilient to worker loss; currently, it has to restart entirely.
-
Performance tuning:
Performance today is good, but not yet at peak hardware speeds. We can improve this in a few ways:
- Hiding disk I/O
- Using more memory when appropriate for smaller shuffles
- Improved batching of small operations
- More efficient serialization
To follow along with the development, subscribe to the tracking issue on GitHub.
Summary
Shuffling data is a common operation in dataframe workloads.
Since 2023.2.1, Dask defaults to P2P shuffling for distributed clusters and shuffles data faster and at constant memory.
This improvement unlocks previously un-runnable workload sizes and efficiently uses your clusters.
Finally, P2P shuffling demonstrates extending Dask to add new paradigms while leveraging the foundations of its distributed engine.
Share results in this discussion thread or follow development at this tracking issue.
blog comments powered by Disqus