Dask Demo Day November 2022
By Richard Pelgrim (Coiled)
Once a month, the Dask Community team hosts Dask Demo Day: an informal and fun online hangout where folks can showcase new or lesser-known Dask features and the rest of us can learn about all the things we didn’t know Dask could do 😁
November’s Dask Demo Day had five great demos. We learned about:
- Visualizing 2-billion lightning flashes with Dask, RAPIDS and Datashader
- The new Dask CLI
- The Dask-Optuna integration for distributed hyperparameter optimization
- Dask-Awkward
- Profiling your Dask code with Dask-PySpy
This blog gives you a quick overview of the five demos and demonstrates how they might be useful to you. You can watch the full recording below.
Visualization at Lightning Speed
Would it be possible to interactively visualize all the lightning strikes in his dataset, Kevin Tyle (University of Albany) recently asked himself. In this demo, Kevin shows you how he leveraged CUDA, RAPIDS-AI, Dask and Datashader to build a smooth interactive visualization of 8 years’ worth of lightning strikes. That’s over 2 billion rows of data.
Kevin shows you how to finetune performance of such a large-scale data processing workflow by:
- Leveraging GPUs
- Using a Dask cluster to maximize hardware usage
- Making smart choices about file types

Watch the full demo or read more about high-performance visualization strategies with Dask and Datashader.
The New Dask CLI
During the Dask Sprint at SciPy this year, a group of Dask maintainers began work on an upgraded, high-level Dask CLI. Doug Davis (Anaconda) walks us through how the CLI works and all the things you can do with it. After installing dask, you can access the CLI by typing dask into your terminal. The tool is designed to be easily extensible by anyone working on Dask. Doug shows you how to add your own components to the Dask CLI.
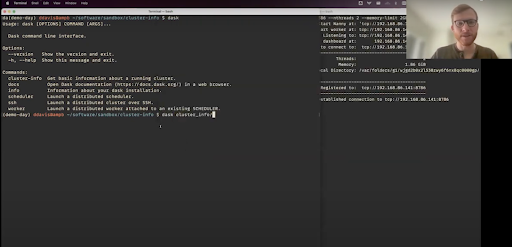
Watch the full demo or read the Dask CLI documentation.
XGBoost HPO with Dask and Optuna
Have you ever wanted to speed up your hyperparameter searches by running them in parallel? James Bourbeau (Coiled) shows you how you can use the brand-new dask-optuna integration to run hundreds of hyperparameter searches in parallel on a Dask cluster. Running your Optuna HPO searches on a Dask cluster requires only two changes to your existing optuna code. After making those changes, we’re then able to run 500 HPO iterations in parallel in 25 seconds.
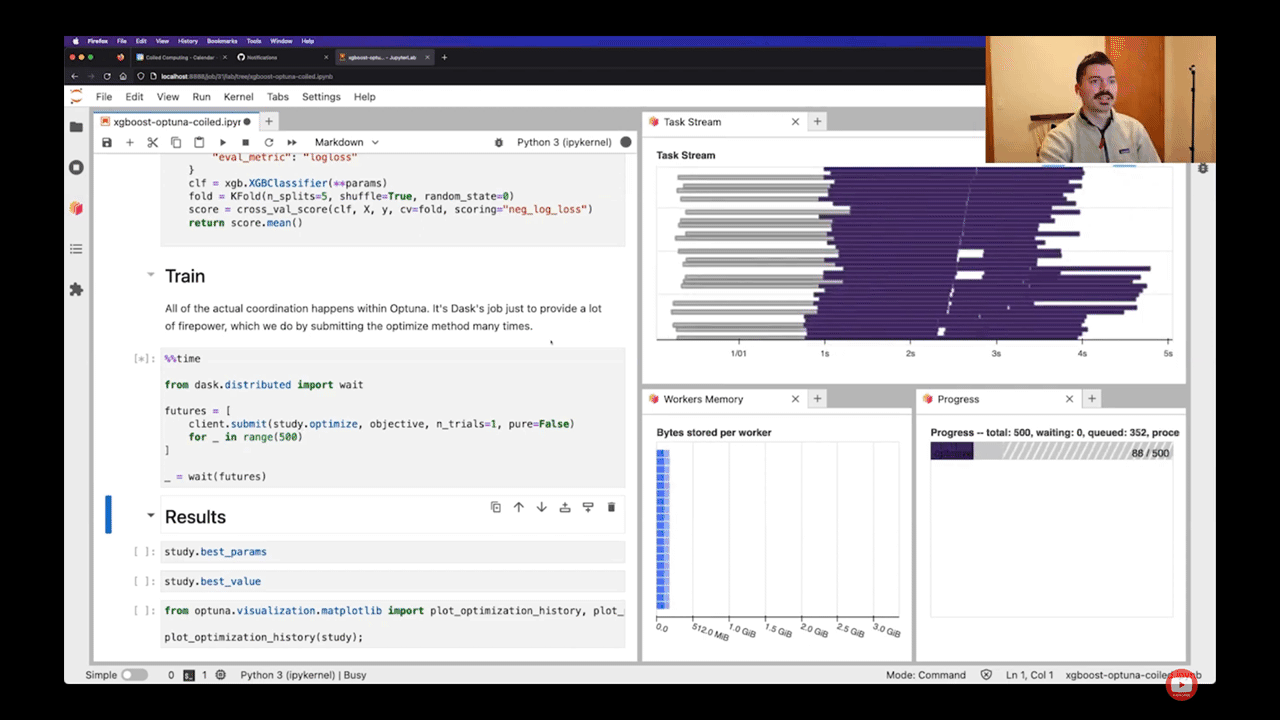
Watch the full demo.
Dask for Awkward Arrays
The PyData ecosystem has historically focused on rectilinear data structures like DataFrames and regular arrays. Awkward Arrays brings NumPy-like operations to non-rectilinear data structures and dask-awkward enables you to work with awkward arrays on a distributed cluster in parallel. Doug Davis (Anaconda) walks you through a quick demo of how to use dask-awkward on a local cluster. This is a helpful tool if you find yourself working with nested data structures at scale.
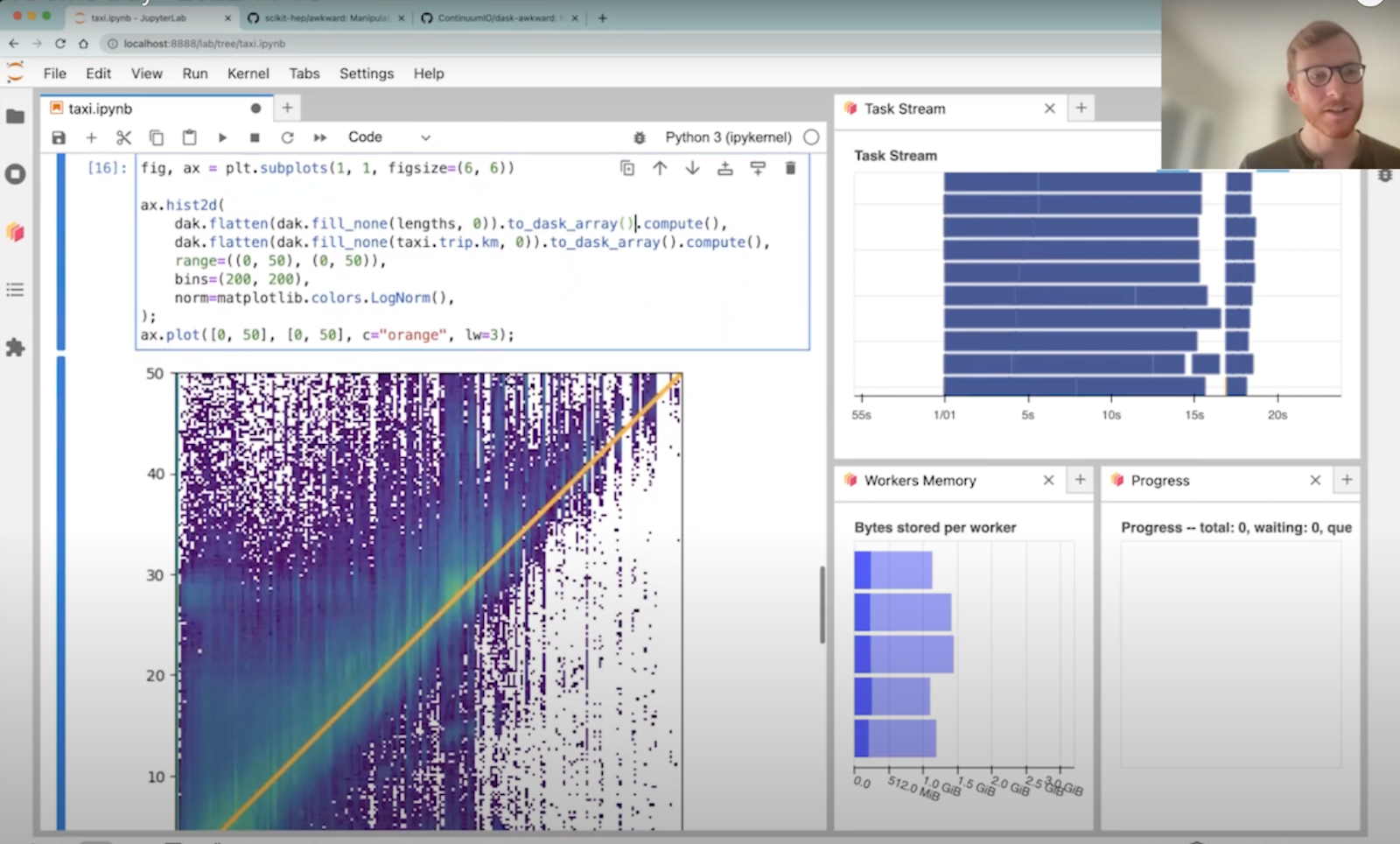
Watch the full demo.
Profiling Dask on a Cluster with py-spy
py-spy is a Python profiler that lets you dig deeper into your code than just your Python functions. Gabe Joseph (Coiled) shows you how you can use dask-pyspy to profile code on a Dask cluster. By digging down into compiled code, dask-pyspy is able to discover valuable insights about why your Dask code might be running slow and what you might be able to do to resolve this.
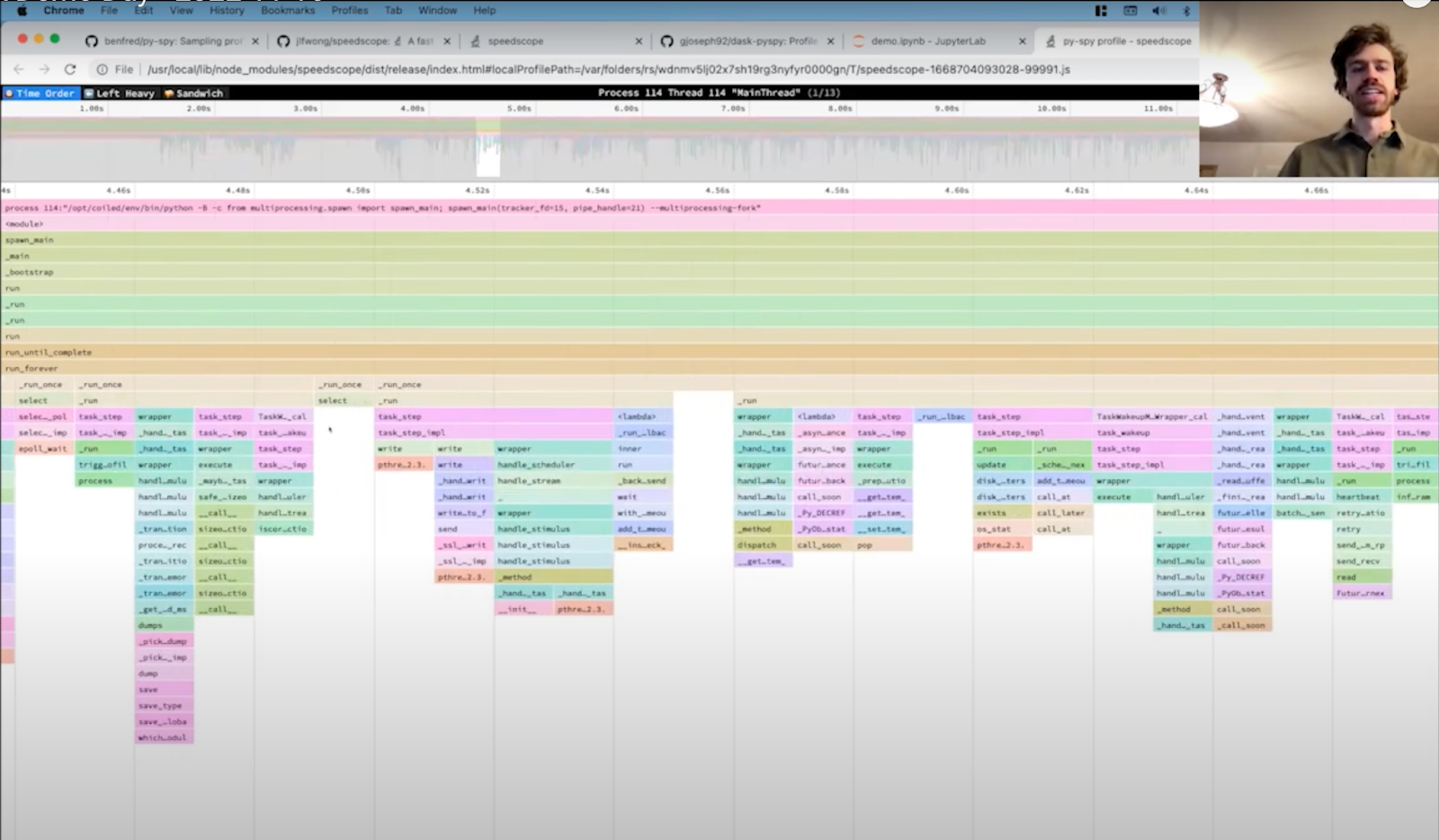
Watch the full demo.
Join us for the next Demo Day!
Dask Demo Day is a great opportunity to learn about the latest developments and features in Dask. It’s also a fun hangout where you can ask questions and interact with some of Dask’s core maintainers in an informal, casual online setting. We’d love to see you at the next Demo Day on December 15th!
Curious how you can stay connected and find out about the latest Dask news and events?
You can:
- follow us on Twitter @dask_dev
- subscribe to the Dask newsletter by sending a blank email to [email protected]
- subscribe to the Dask community calendar
blog comments powered by Disqus