Choosing good chunk sizes in Dask
By Genevieve Buckley
Summary
Confused about choosing a good chunk size for Dask arrays?
Array chunks can’t be too big (we’ll run out of memory), or too small (the overhead introduced by Dask becomes overwhelming). So how can we get it right?
It’s a two step process:
- First, start by choosing a chunk size similar to data you know can be processed entirely within memory (i.e. without Dask), using these rough rules of thumb.
- Then, watch the Dask dashboard task stream and worker memory plots, and adjust if needed. Here are the signs to watch out for.
Contents
- What are Dask array chunks?
- Too small is a problem
- Too big is also a problem
- Choosing an initial chunk size
- Using the Dask dashboard
- Rechunking arrays
- Unmanaged memory
- Thanks for reading
What are Dask array chunks?
Dask arrays are big structures, made out of many small chunks. Typically, each small chunk is an individual numpy array, and they are arranged together to make a much larger Dask array.

You can find more information about Dask array chunks on this page of the documentation: https://docs.dask.org/en/latest/array-chunks.html
How do I know what chunks my array has?
If you have a Dask array, you can use the chunksize or chunks attribues to see information about the chunks. You can also visualize this with the Dask array HTML representation.
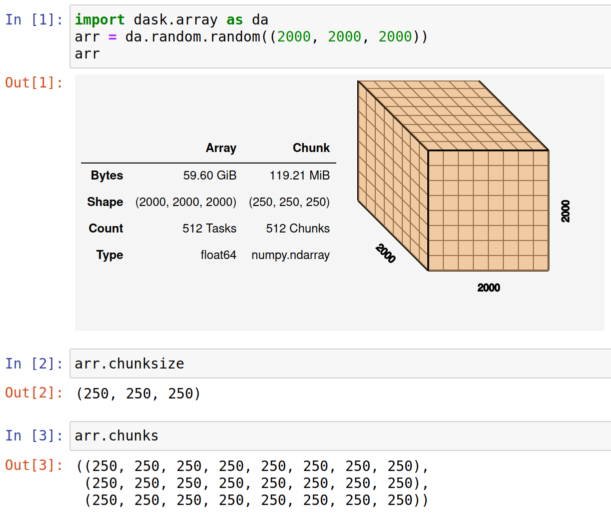
arr.chunksize shows the largest chunk size. For arrays where you expect roughly uniform chunk sizes, this is a good way to summarize chunk size information.
arr.chunks shows fully explicit sizes of all chunks along all dimensions within the Dask array (see item 3 here). This is more verbose, and is a good choice with arrays that have irregular chunks.
Too small is a problem
If array chunks are too small, it’s inefficient. Why is this?
Using Dask introduces some amount of overhead for each task in your computation. This overhead is the reason the Dask best practices advise you to avoid too-large graphs. This is because if the amount of actual work done by each task is very tiny, then the percentage of overhead time vs useful work time is not good.
Typically, the Dask scheduler takes 1 millisecond to coordinate a single task. That means we want the computation time for each task to be comparitively larger, eg: seconds instead of milliseconds.
It might be hard to understand this intuitively, so here’s an analogy. Let’s imagine we’re building a house. It’s a pretty big job, and if there were only one worker it would take much too long to build. So we have a team of workers and a site foreman. The site foreman is equivalent to the Dask scheduler: their job is to tell the workers what tasks they need to do.
Say we have a big pile of bricks to build a wall, sitting in the corner of the building site. If the foreman (the Dask scheduler) tells workers to go and fetch a single brick at a time, then bring each one to where the wall is being built, you can see how this is going to be very slow and inefficient! The workers are spending most of their time moving between the wall and the pile of bricks. Much less time is going towards doing the actual work of mortaring bricks onto the wall.
Instead, we can do this in a smarter way. The foreman (Dask scheduler) can tell the workers to go and bring one full wheelbarrow load of bricks back each time. Now workers are spending much less time moving between the wall and the pile of bricks, and the wall will be finished much quicker.
Too big is also a problem
If the Dask array chunks are too big, this is also bad. Why? Chunks that are too large are bad because then you are likely to run out of working memory. You may see out of memory errors happening, or you might see performance decrease substantially as data spills to disk.
When too much data is loaded in memory on too few workers, Dask will try to spill data to disk instead of crashing. Spilling data to disk makes things run very slowly, because all the extra read/write operations to disk. Things don’t just get a little bit slower, they get a LOT slower, so it’s smart to watch out for this.
To watch out for this, look at the worker memory plot on the Dask dashboard. Orange bars are a warning you are close to the limit, and gray means data is being spilled to disk - not good! For more tips, see the section on using the Dask dashboard below.
Choosing an initial chunk size
Rough rules of thumb
- If you already created a prototype, which may not involve Dask at all, using a small subset of the data you intend to process, you’ll have a clear idea of what size of data can be processed easily for this workflow. You can use this knowledge to choose similar sized chunks in Dask.
- Some people have observed that chunk sizes below 1MB are almost always bad. Chunk size between 100MB and 1GB are generally good, going over 1 or 2GB means you have a really big dataset and/or a lot of memory available per core,
- Upper bound: Avoid too large task graphs. More than 10,000 or 100,000 chunks may start to perform poorly.
- Lower bound: To get the advantage of parallelization, you need the number of chunks to at least equal the number of worker cores available (or better, the number of worker cores times 2). Otherwise, some workers will stay idle.
- The time taken to compute each task should be much larger than the time needed to schedule the task. The Dask scheduler takes roughly 1 millisecond to coordinate a single task, so a good task computation time would be measured in seconds (not milliseconds).
Chunks should be aligned with array storage on disk
If you are reading data from disk, the storage structure will inform what shape your Dask array chunks should be. For best performance, choose chunks that are well aligned with the way data is stored.
From the Dask best practices on how to orient your chunks:
When reading data you should align your chunks with your storage format. Most array storage formats store data in chunks themselves. If your Dask array chunks aren’t multiples of these chunk shapes then you will have to read the same data repeatedly, which can be expensive. Note though that often storage formats choose chunk sizes that are much smaller than is ideal for Dask, closer to 1MB than 100MB. In these cases you should choose a Dask chunk size that aligns with the storage chunk size and that every Dask chunk dimension is a multiple of the storage chunk dimension.
Some examples of data storage structures on disk include:
- A HDF5 or Zarr array. The size and shape of chunks/blocks stored on disk should align well with the Dask array chunks you select.
- A folder full of tiff files. You might decide that each tiff file should become a single chunk in the Dask array (or that multiple tiff files should be grouped into a single chunk).
Using the Dask dashboard
The second part of choosing a good chunk size is monitoring the Dask dashboard to see if you need to make any adjustments.
If you’re not very familiar with the Dask dashboard, or you just sometimes forget where to find certain dashboard plots (like the worker memory plot), then you’ll probably enjoy these quick video tutorials:
- Intro to the Dask dashboard (18 minute video)
- Dask Jupyterlab extension (6 minute video)
- Dask dashboard documentation
We recommend always having the dashboard up when you’re working with Dask. It’s a fantastic way to get a sense of what’s working well, or poorly, so you can make adjustments.
What to watch for on the dashboard
Bad signs to watch out for include:
- Lots of white space in the task stream plot is a bad sign. White space means nothing is happening. Chunks may be too small.
- Lots and lots of red in the task stream plot is a bad sign. Red means worker communication. Dask workers need some communication, but if they are doing almost nothing except communication then there is not much productive work going on.
- On the worker memory plot, watch out for orange bars which are a sign you are getting close to the memory limit. Chunks may be too big.
- On the worker memory plot, watch out for grey bars which mean data is being spilled to disk. Chunks may be too big.
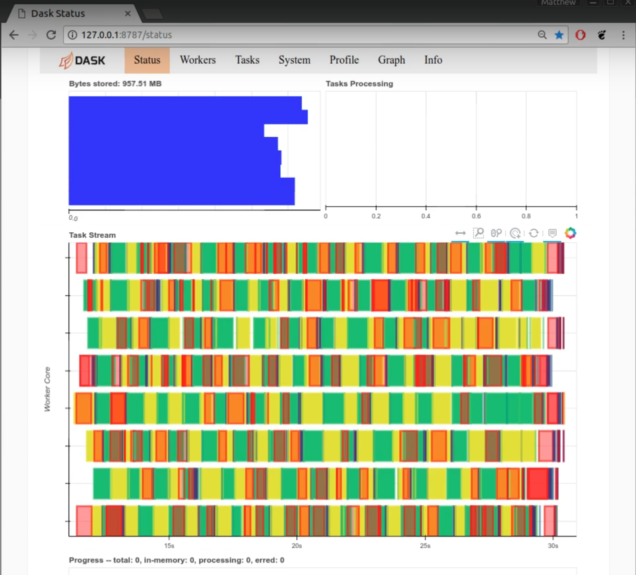
Here is an example of the Dask dashboard during a good computation (time 6:12 in this video).
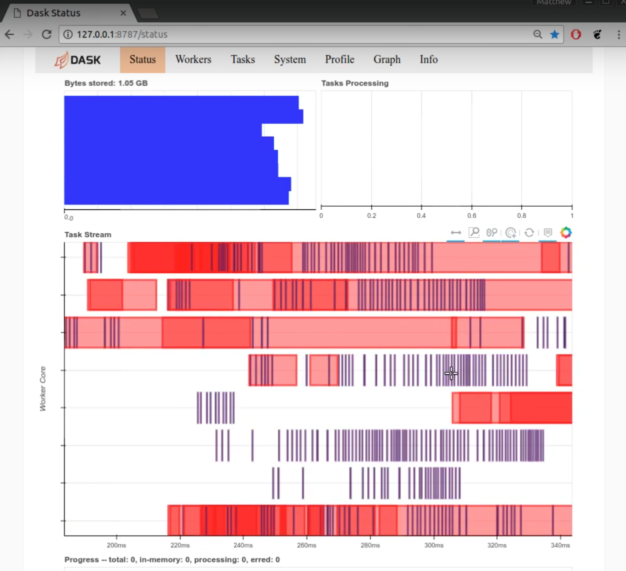
For comparison, here is an example of the Dask dashboard during a bad computation (time 6:57 in this video).
In this example, it’s inefficient because the chunks are much too small, so we see a lot of white space and red worker communication in the task stream plot.
Rechunking arrays
If you need to change the chunking of a Dask array in the middle of a computation, you can do that with the rechunk method.
rechunked_array = original_array.rechunk(new_shape)
Warning: Rechunking Dask arrays comes at a cost.
- The Dask graph must be rearranged to accomodate the new chunk structure. This happens immediately, and will block any other interaction with python until Dask has rearranged the task graph.
- This also inserts new tasks into the Dask graph. At compute time, there are now more tasks to execute.
For these reasons, it is best to choose a good initial chunk size and avoid rechunking.
However, sometimes the data is stored on disk is not well aligned and rechunking may be necessary. For an example of this, here is Draga Doncila Pop talking about chunk alignment with satellite image data.
The rechunker library can be useful in these situations:
Rechunker takes an input array (or group of arrays) stored in a persistent storage device (such as a filesystem or a cloud storage bucket) and writes out an array (or group of arrays) with the same data, but different chunking scheme, to a new location. Rechunker is designed to be used within a parallel execution framework such as Dask.
Unmanaged memory
Last, remember that you don’t only need to consider the size of the array chunks in memory, but also the working memory consumed by your analysis functions. Sometimes that is called “unmanaged memory” in Dask.
“Unmanaged memory is RAM that the Dask scheduler is not directly aware of and which can cause workers to run out of memory and cause computations to hang and crash.” – Guido Imperiale
Here are some tips for handling unmanaged memory:
- Tackling unmanaged memory with Dask (Coiled blogpost) by Guido Imperiale
- Handle Unmanaged Memory in Dask (8 minute video)
Thanks for reading
We hope this was helpful figuring out how to choose good chunk sizes for Dask. This blogpost was inspired by this twitter thread. If you’d like to follow Dask on Twitter, you can do that at https://twitter.com/dask_dev
blog comments powered by Disqus