Stability of the Dask library
By Matthew Rocklin
Dask is moving fast these days. Sometimes we break things as a result.
Historically this hasn’t been a problem, according to our survey last year most users were fairly happy with Dask’s stability.
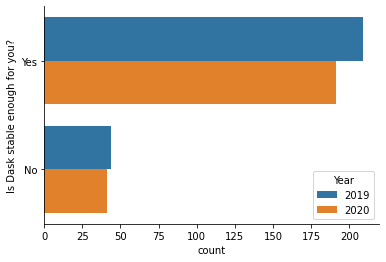
However the last year has seen a lot of evolution of the project, which in turn causes code churn. This can cause friction for downstream users today, but also means more-than-incremental changes for the future. We’ve optimized a little bit for long-term growth over short-term stability.
Motivation for change
There are two structural things driving some of these changes:
- An increase in computational scale
- An increase in organizational scale
Computational Scale
Dask today is used across a wider range of problems, a more diverse set of hardware, and at larger scales more routinely than before.
Addressing this increase in scale across many dimensions has caused us to redesign Dask’s internal infrastructure in several ways.
- We’ve changed how Dask graphs are represented and communicated to the scheduler
- We’ve pulled out Dask’s internal state machines and made them more formalized
- We’ve rewritten large chunks of the scheduler in Cython
- We’ve overhauled how we serialize messages that go between all Dask servers
- We’re now tracking memory with much finer granularity than we did before
- … and more
We’ve been doing all of these internal changes with minimal impact to the myriad of downstream user communities (Xarray, Prefect, RAPIDS, XGBoost, …). This is largely due to those downstream developer communities, who help to identify, isolate, and work through the subtle tremors that occur on the surface when we make these subsurface shifts.
Organizational scale
Historically Dask’s core was maintained by a relatively small set of people,
mostly at Anaconda.
There were dozens of developers that worked on various dask-foo projects, but
only a small group that thought about things like serialization, state
machines, and so on.
In particular I personally tracked every issue and knew the entire project.
Whenever a potential conflict arose I was usually able to identify it early.
This has all changed dramatically.
First, there are now several multi-company teams working on different parts of Dask internals.
Second, we’ve also taken some time to redesign parts of Dask internals to make them more maintainable. Dask scheduling is like a finely made clock. Historically parts of that clock were built and designed by individuals with a craftsman-like approach. Now we’re redesigning things with more of a group mindset. This results in more maintainable designs, but it also means that we’re taking apart the clock and putting it back together. It takes a little while to find all of the missing parts :)
How this affects you today
This all started around when we switched to Calendar Versioning at the end of last year
(Dask version 2.30.1 rolled over into 2020.12.0 last December). You may
have noticed
- an increased sensitivity to version mismatches (as we change the Dask protocol different versions of Dask can no longer talk to each other well)
- releases with stability issues (2020.12 was particularly rough)
- tighter pinning between dask and distributed versions during releases
How this will affect you
We’ve merged in a PR to change the default behavior when moving high level graphs to the scheduler for Dask Dataframes. This should result in much less delay when submitting large computations and almost no delay in optimization. It also opens up a conduit for us to send a lot more semantic information to the scheduler about your computation, which can result in new visualizations and smarter scheduling in the future.
It will also probably break some things.
To be clear, all tests pass among Dask, distributed, xarray, prefect, rapids, and other downstream projects. We’ve done our homework here, but almost certainly we’ve missed something.
This is only one of several larger changes happening in the coming months. We appreciate your patience and your engagement as we make some of these larger shifts. For better or worse end users are the final testing suite :)
blog comments powered by Disqus