Last Year in Review From the SciPy 2020 Maintainers Track
By Jacob Tomlinson (NVIDIA)
We recently enjoyed the 2020 SciPy conference from the comfort of our own homes this year. The 19th annual Scientific Computing with Python conference was a virtual conference this year due to the global pandemic. The annual SciPy Conference brought together over 1500 participants from industry, academia, and government to showcase their latest projects, learn from skilled users and developers, and collaborate on code development.
As part of the maintainers track we presented an update on Dask.
Video
You can find the video on the SciPy YouTube channel. The Dask update runs from 0:00-19:30.
Slides
Talk Summary
Here’s a summary of the main topics covered in the talk. You can also check out the original thread on Twitter.
Community overview
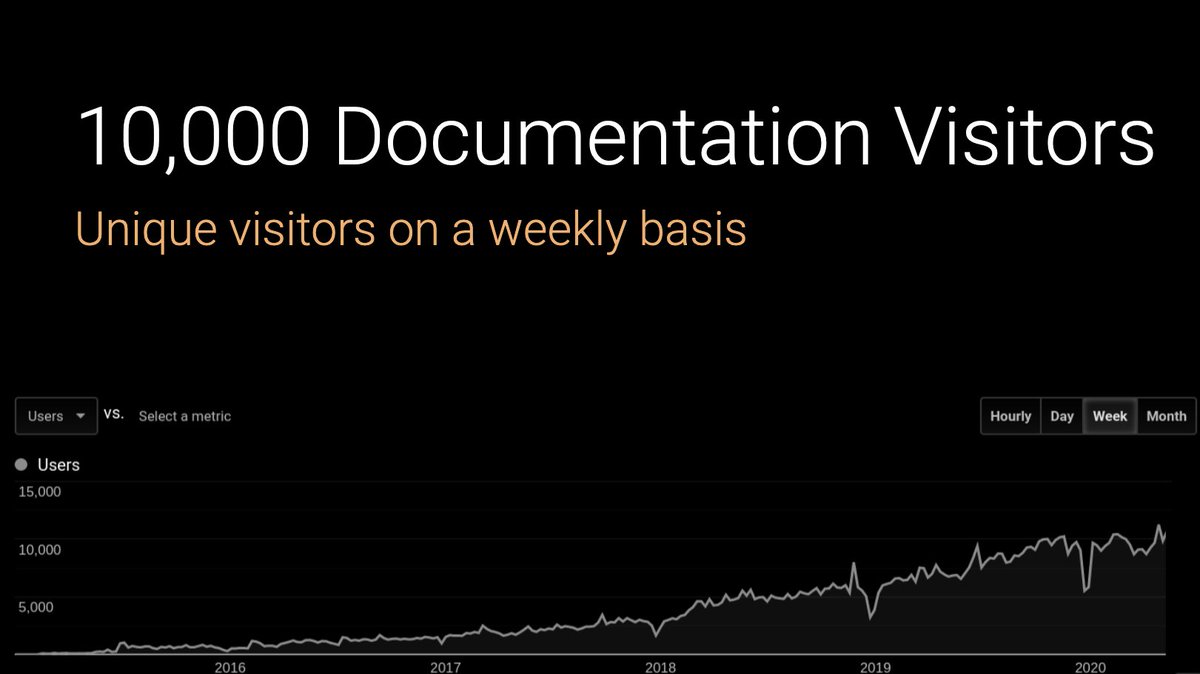
We’ve been trying to gauge the size of our community lately. The best proxy we have right now is the number of weekly visitors to the Dask documentation. Which currently stands at around 10,000.
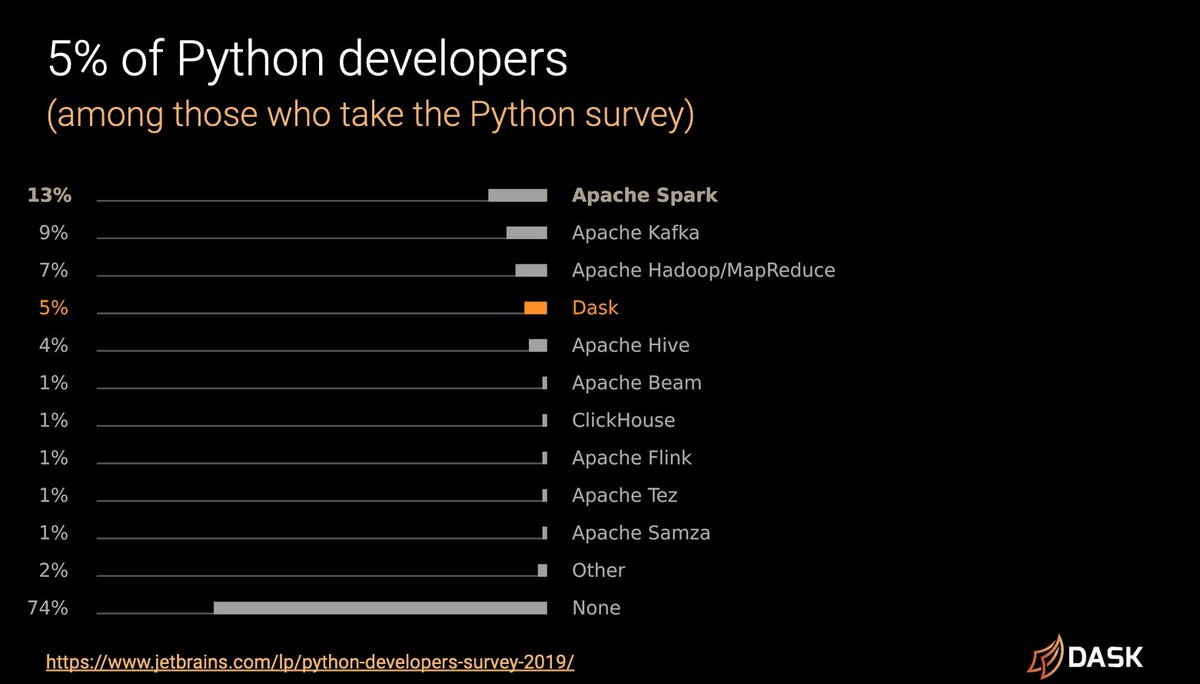
Dask also came up in the Jetbrains Python developer survey. We were excited to see 5% of all the Python developers who filled out the survey said they use Dask. Which shows health in the PyData community as well as Dask.
We are running our own survey at the moment. If you are a Dask user please take a few minutes to fill it out. We would really appreciate it.

Community events
In February we had an in-person Dask Summit where a mixture of OSS maintainers and institutional users met. We had talks and workshops to help figure out our challenges and set our direction.

The Dask community also has a monthly meeting! It is held on the first Thursday of the month at 10:00 US Central Time. If you’re a Dask user you are welcome to come to hear updates from maintainers and share what you’re working on.
Community projects
There are many projects built on Dask. Looking at the preliminary results from the 2020 Dask survey shows some that are especially popular.
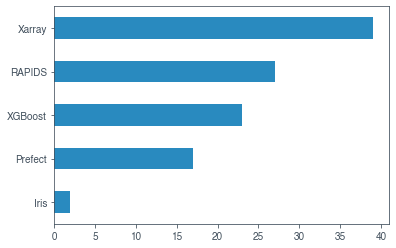
Let’s take a look at each of those.
Xarray
Xarray allows you to work on multi-dimensional datasets that have supporting metadata arrays in a Pandas-like way.

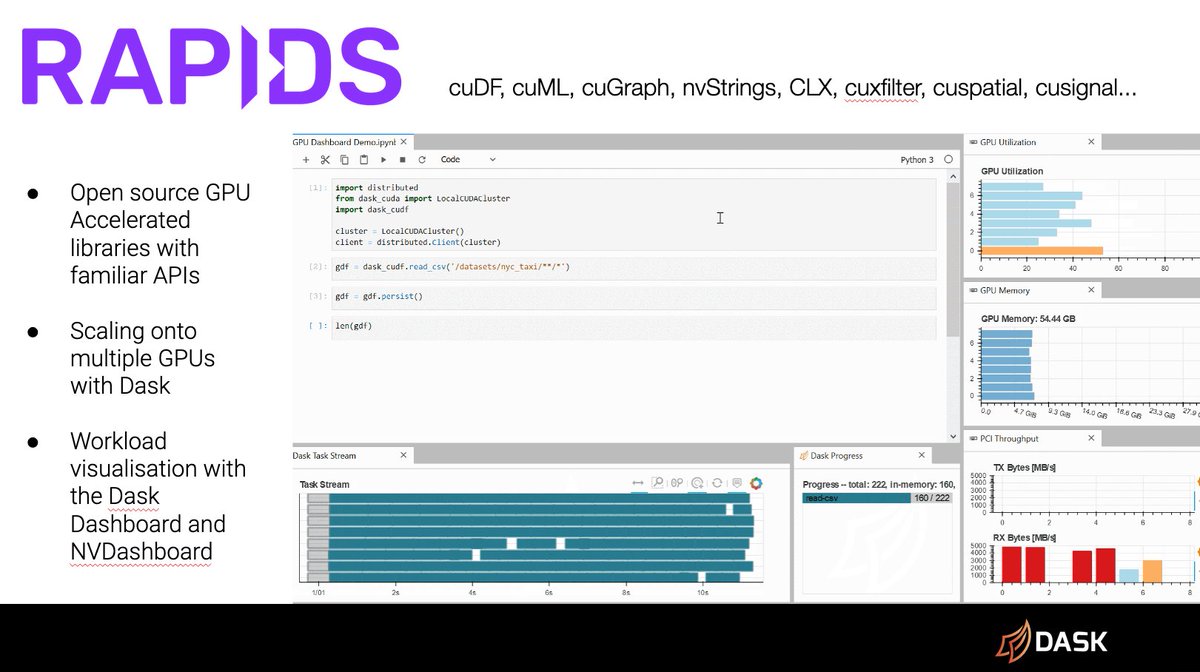
RAPIDS
RAPIDS is an open-source suite of GPU accelerated Python libraries. Using these tools you can execute end-to-end data science and analytics pipelines entirely on GPUs. All using familiar PyData APIs.
BlazingSQL
BlazingSQL builds on RAPIDS and Dask to provide an open-source distributed, GPU accelerated SQL engine.

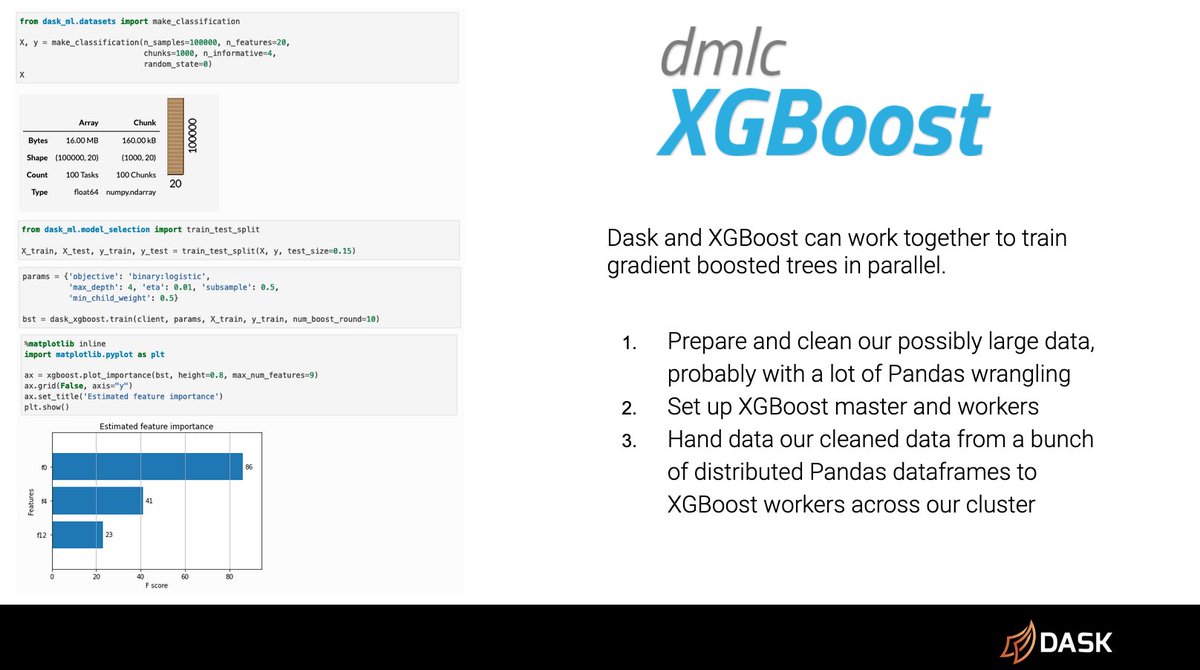
XGBoost
While XGBoost has been around for a long time you can now prepare your data on your Dask cluster and then bootstrap your XGBoost cluster on top of Dask and hand the distributed dataframes straight over.
Prefect
Prefect is a workflow manager which is built on top of Dask’s scheduling engine. “Users organize Tasks into Flows, and Prefect takes care of the rest.”

Iris
Iris, part of the SciTools suite of tools, uses the CF data model giving you a format-agnostic interface for working with your data. It excels when working with multi-dimensional Earth Science data, where tabular representations become unwieldy and inefficient.

More tools
These are the tools our community have told us they like so far. But if you use something which didn’t make the list then head to our survey and let us know! According to PyPI there are many more out there.
User groups
There are many user groups who use Dask. Everything from life sciences, geophysical sciences and beamline facilities to finance, retail and logistics. Check out the great “Who uses Dask?” talk from Matthew Rocklin for more info.

For profit companies
There has been an increase in for-profit companies building tools with Dask. Including Coiled Computing, Prefect and Saturn Cloud.

We’ve also seen large companies like Microsoft’s Azure ML team contributing a cluster manager to Dask Cloudprovider. This helps folks get up and running with Dask on AzureML quicker and easier.
Recent improvements
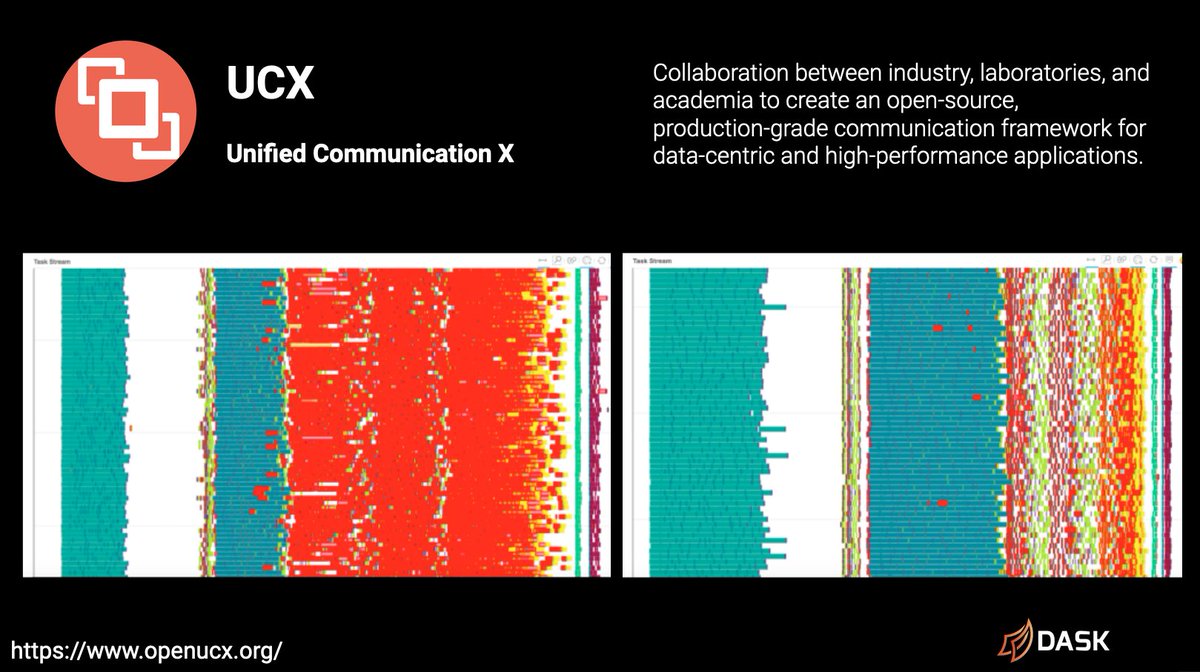
Communications
Moving on to recent improvements there has been a lot of work to get Open UCX supported as a protocol in Dask. Which allows worker-worker communication to be accelerated vastly with hardware that supports Infiniband or NVLink.
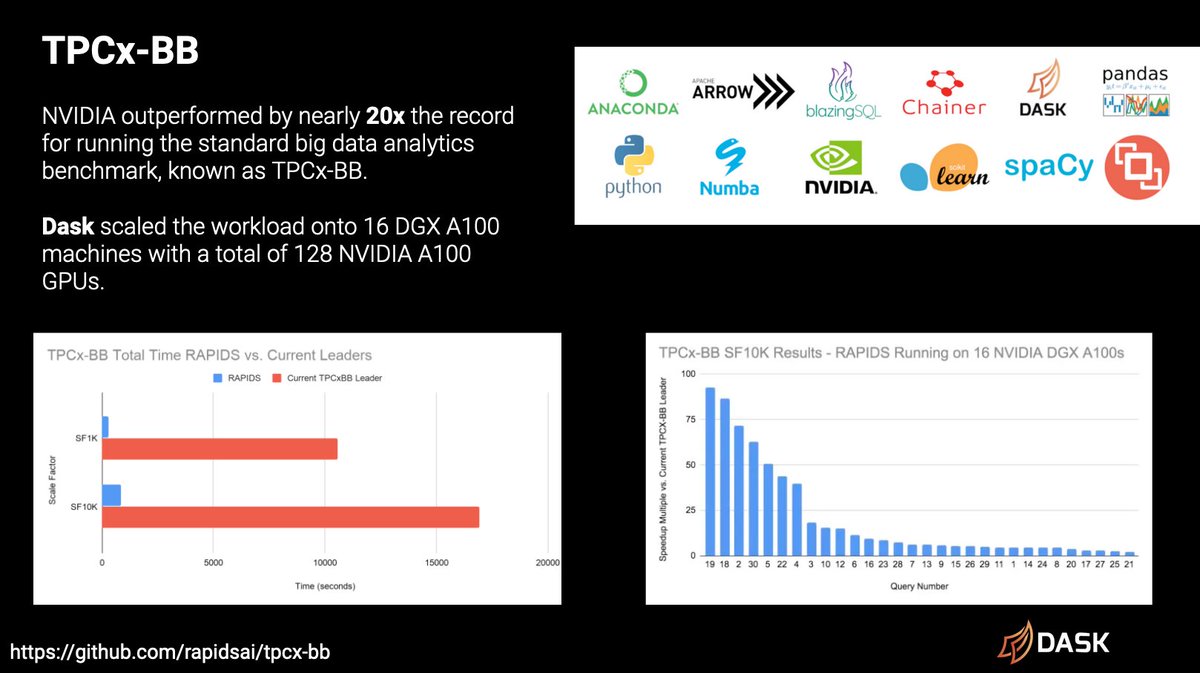
There have also been some recent announcements around NVIDIA blowing away the TPCx-BB benchmark by outperforming the current leader by 20x. This is a huge success for all the open-source projects that were involved, including Dask.
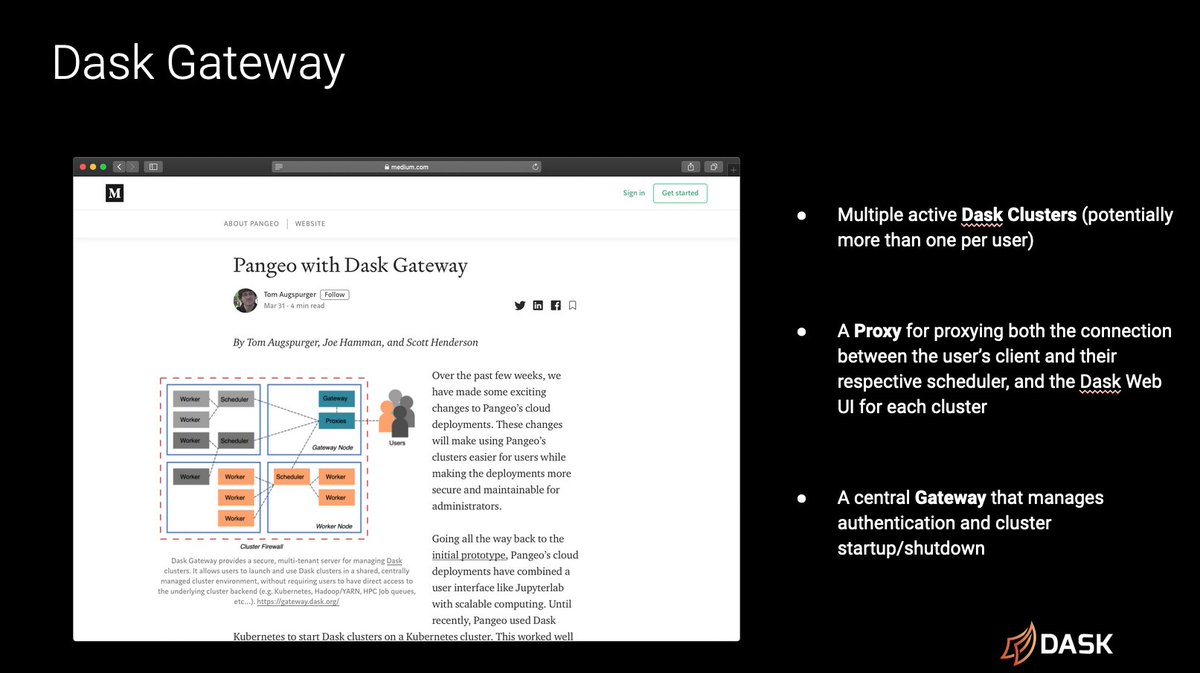
Dask Gateway
We’ve seen increased adoption of Dask Gateway. Many institutions are using it as a way to provide their staff with on-demand Dask clusters.
Cluster map plot (aka ‘pew pew pew’)
The update that got the most 👏 feedback from the SciPy 2020 attendees was the Cluster Map Plot (known to maintainers as the “pew pew pew” plot). This plot shows a high-level overview of your Dask cluster scheduler and workers and the communication between them.
Next steps
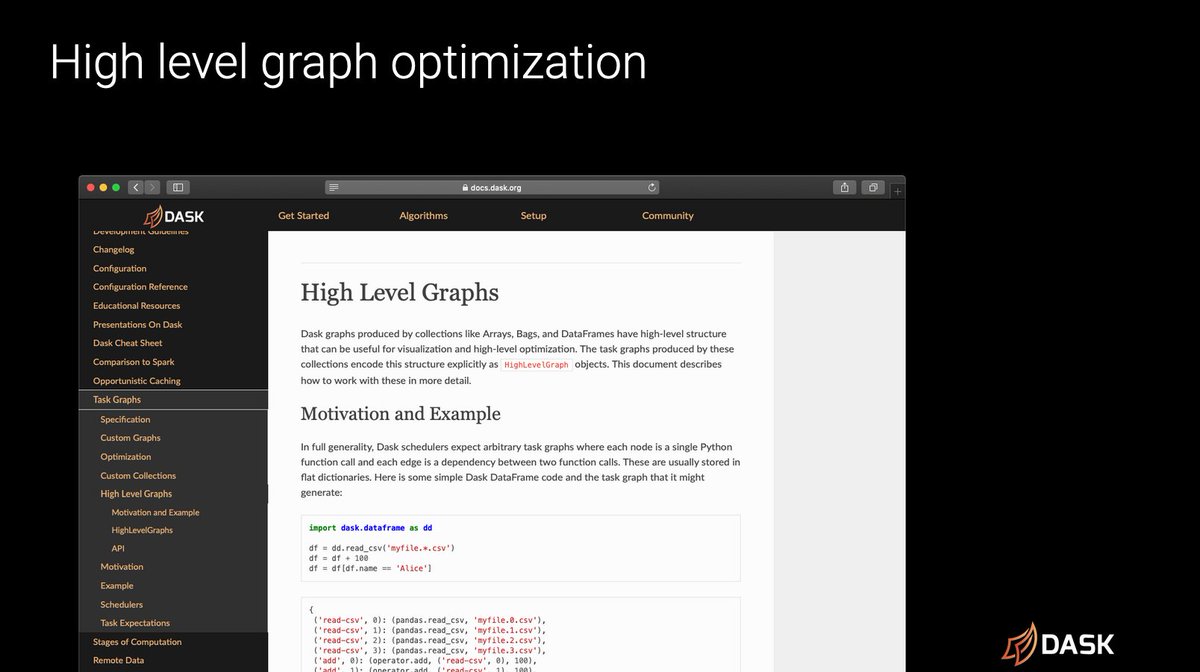
High-level graph optimization
To wrap up with what Dask is going to be doing next we are going to be continuing to work on high-level graph optimization.
Scheduler performance
With feedback from our community we are also going to be focussing on making the Dask scheduler more performant. There are a few things happening including a Rust implementation of the scheduler, dynamic task creation and ongoing benchmarking.

Chan Zuckerberg Foundation maintainer post
Lastly I’m excited to share that with funding from the Chan Zuckerberg Foundation, Dask will be hiring a maintainer who will focus on growing usage in the biological sciences field. If that is of interest to you keep an eye on our twitter account for more announcements.
blog comments powered by Disqus