Experiments in High Performance Networking with UCX and DGX
By Matthew Rocklin, Rick Zamora
This post is about experimental and rapidly changing software. Code examples in this post should not be relied upon to work in the future.
Executive Summary
This post talks about connecting UCX, a high performance networking library, to Dask, a parallel Python library, to accelerate communication-heavy workloads, particularly when using GPUs.
Additionally, we do this work on a DGX, a high-end multi-CPU multi-GPU machine with a complex internal network. Working in this context was good to force improvements in setting up Dask in heterogeneous situations targeting different network cards, CPU sockets, GPUs, and so on..
Motivation
Many distributed computing workloads are communication-bound. This is common in cases like the following:
- Dataframe joins
- Machine learning algorithms
- Complex array computations
Communication becomes a bigger bottleneck as we accelerate our computation, such as when we use GPUs for computing.
Historically, high performance communication was only available using MPI, or with custom solutions. This post describes an effort to get close to the communication bandwidth of MPI while still maintaining the ease of programmability and accessibility of a dynamic system like Dask.
UCX, Python, and Dask
To get high performance networking in Dask, we wrapped UCX with Python and then connected that to Dask.
The OpenUCX project provides a uniform API around various high performance networking libraries like InfiniBand, traditional networking protocols like TCP/shared memory, and GPU-specific protocols like NVLink. It is a layer beneath something like OpenMPI (the main user of OpenUCX today) that figures out which networking system to use.
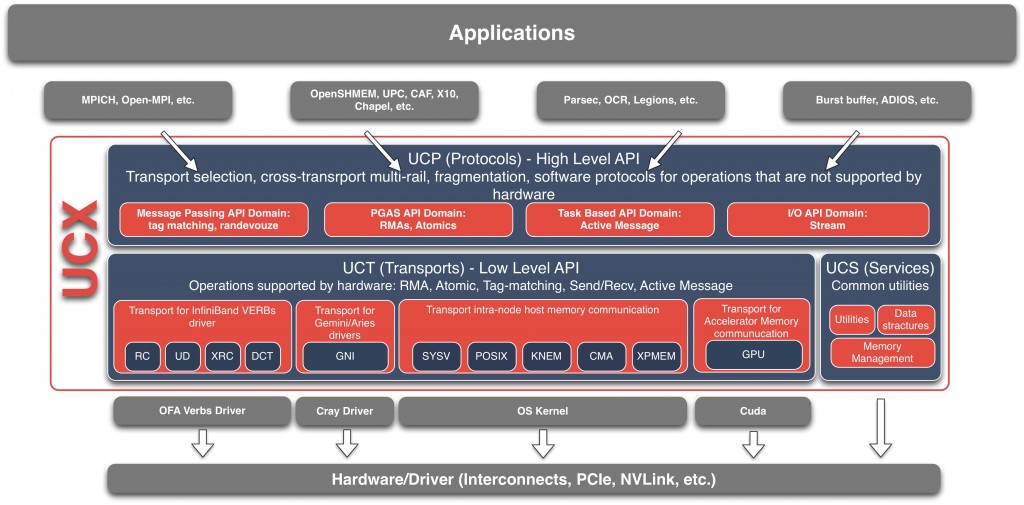
Python users today don’t have much access to these network libraries, except through MPI, which is sometimes not ideal. (Try searching for “infiniband” on PyPI.)
This led us to create UCX-Py
.
UCX-Py is a Python wrapper around the UCX C library, which provides a Pythonic
API, both with blocking syntax appropriate for traditional HPC programs, as
well as a non-blocking async/await syntax for more concurrent programs (like
Dask).
For more information on UCX I recommend watching Akshay’s UCX
talk
from the GPU Technology Conference 2019.
Note: UCX-Py was primarily developed by Akshay Venkatesh (UCX, NVIDIA) Tom Augspurger (Dask, Pandas, Anaconda), and Ben Zaitlen (NVIDIA, RAPIDS, Dask))
We then extended Dask communications to optionally use UCX.
If you have UCX and UCX-Py installed, then you can use the ucx:// protocol in
addresses or the --protocol ucx flag when starting things up, something like
this.
$ dask-scheduler --protocol ucx
Scheduler started at ucx://127.0.0.1:8786
$ dask-worker ucx://127.0.0.1:8786
>>> from dask.distributed import Client
>>> client = Client('ucx://127.0.0.1:8786')
Experiment
We modified our SVD with Dask and CuPy benchmark benchmark to use the UCX protocol for inter-process communication and ran it on half of a DGX machine, using four GPUs. Here is a minimal implementation of the UCX-enabled code:
import cupy
import dask
import dask.array
from dask.distributed import Client, wait
from dask_cuda import DGX
# Define DGX cluster and client
cluster = DGX(CUDA_VISIBLE_DEVICES=[0, 1, 2, 3])
client = Client(cluster)
# Create random data
rs = dask.array.random.RandomState(RandomState=cupy.random.RandomState)
x = rs.random((1000000, 1000), chunks=(10000, 1000))
x = x.persist()
# Perform distributed SVD
u, s, v = dask.array.linalg.svd(x)
u, s, v = dask.persist(u, s, v)
_ = wait([u, s, v])
By using UCX the overall communication times are reduced by an order of
magnitude. To produce the task-stream figures below, the benchmark was run on a
DGX-1 with CUDA_VISIBLE_DEVICES=[0,1,2,3]. It is clear that the red task
bars, corresponding to inter-process communication, are significantly
compressed. Communications that were taking 500ms-1s before now take around 20ms.
Before UCX:
After UCX:
Diving into the Details
On a GPU using NVLink we can get somewhere between 5-10 GB/s throughput between pairs of GPUs. On a CPU this drops down to 1-2 GB/s (which seems well below optimal). These speeds can affect all Dask workloads (array, dataframe, xarray, ML, …), but when the proper hardware is present, other bottlenecks may occur, such as serialization when dealing with text or JSON-like data.
This of course, depends on this fancy networking hardware being present. On the GPU example above we’re mostly relying on NVLink, but we would also get improved performance on an HPC InfiniBand network or even on a single laptop machine using shared memory transports.
The examples above was run on a DGX machine, which includes all of these transports and more (as well as numerous GPUs).
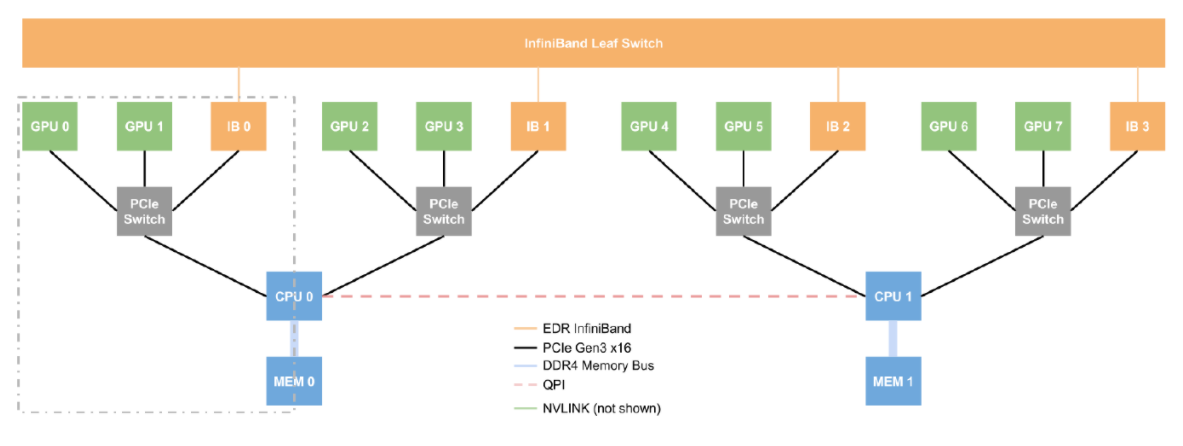
DGX
The test machine used above was a DGX-1, which has eight GPUs, two CPU sockets, four Infiniband network cards, and a complex NVLink arrangement. This is a good example of non-uniform hardware. Certain CPUs are closer to certain GPUs and network cards, and understanding this proximity has an order-of-magnitude effect on performance. This situation isn’t unique to DGX machines. The same situation arises when we have …
- Multiple workers in one node, with several nodes in a cluster
- Multiple nodes in one rack, with several racks in a data center
- Multiple data centers, such as is the case with hybrid cloud
Working with the DGX was interesting because it forced us to start thinking about heterogeneity, and making it easier to specify complex deployment scenarios with Dask.
Here is a diagram showing how the GPUs, CPUs, and Infiniband cards are connected to each other in a DGX-1:
And here the output of nvidia-smi showing the NVLink, networking, and CPU affinity structure (this is mostly orthogonal to the structure displayed above).
$ nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 ib0 ib1 ib2 ib3
GPU0 X NV1 NV1 NV2 NV2 SYS SYS SYS PIX SYS PHB SYS
GPU1 NV1 X NV2 NV1 SYS NV2 SYS SYS PIX SYS PHB SYS
GPU2 NV1 NV2 X NV2 SYS SYS NV1 SYS PHB SYS PIX SYS
GPU3 NV2 NV1 NV2 X SYS SYS SYS NV1 PHB SYS PIX SYS
GPU4 NV2 SYS SYS SYS X NV1 NV1 NV2 SYS PIX SYS PHB
GPU5 SYS NV2 SYS SYS NV1 X NV2 NV1 SYS PIX SYS PHB
GPU6 SYS SYS NV1 SYS NV1 NV2 X NV2 SYS PHB SYS PIX
GPU7 SYS SYS SYS NV1 NV2 NV1 NV2 X SYS PHB SYS PIX
ib0 PIX PIX PHB PHB SYS SYS SYS SYS X SYS PHB SYS
ib1 SYS SYS SYS SYS PIX PIX PHB PHB SYS X SYS PHB
ib2 PHB PHB PIX PIX SYS SYS SYS SYS PHB SYS X SYS
ib3 SYS SYS SYS SYS PHB PHB PIX PIX SYS PHB SYS X
CPU Affinity
GPU0 0-19,40-59
GPU1 0-19,40-59
GPU2 0-19,40-59
GPU3 0-19,40-59
GPU4 20-39,60-79
GPU5 20-39,60-79
GPU6 20-39,60-79
GPU7 20-39,60-79
Legend:
X = Self
SYS = Traverse PCIe as well as the SMP interconnect between NUMA nodes
NODE = Travrese PCIe as well as the interconnect between PCIe Host Bridges
PHB = Traverse PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Traverse multiple PCIe switches (without PCIe Host Bridge)
PIX = Traverse a single PCIe switch
NV# = Traverse a bonded set of # NVLinks
The DGX was originally designed for deep learning applications. The complex network infrastructure above can be well used by specialized NVIDIA networking libraries like NCCL, which knows how to route things correctly, but is something of a challenge for other more general purpose systems like Dask to adapt to.
Fortunately, in meeting this challenge we were able to clean up a number of related issues in Dask. In particular we can now:
- Specify a more heterogeneous worker configuration when starting up a local cluster dask/distributed #2675
- Learn bandwidth over time dask/distributed #2658
- Add Worker plugins to help handle things like CPU affinity (though this is quite general) dask/distributed #2453
With these changes we’re now able to describe most of the DGX structure as configuration in the Python function below:
import os
from dask.distributed import Nanny, SpecCluster, Scheduler
from distributed.worker import TOTAL_MEMORY
from dask_cuda.local_cuda_cluster import cuda_visible_devices
class CPUAffinity:
""" A Worker plugin to pin CPU affinity """
def __init__(self, cores):
self.cores = cores
def setup(self, worker=None):
os.sched_setaffinity(0, self.cores)
affinity = { # See nvidia-smi topo -m
0: list(range(0, 20)) + list(range(40, 60)),
1: list(range(0, 20)) + list(range(40, 60)),
2: list(range(0, 20)) + list(range(40, 60)),
3: list(range(0, 20)) + list(range(40, 60)),
4: list(range(20, 40)) + list(range(60, 79)),
5: list(range(20, 40)) + list(range(60, 79)),
6: list(range(20, 40)) + list(range(60, 79)),
7: list(range(20, 40)) + list(range(60, 79)),
}
def DGX(
interface="ib",
dashboard_address=":8787",
threads_per_worker=1,
silence_logs=True,
CUDA_VISIBLE_DEVICES=None,
**kwargs
):
""" A Local Cluster for a DGX 1 machine
NVIDIA's DGX-1 machine has a complex architecture mapping CPUs,
GPUs, and network hardware. This function creates a local cluster
that tries to respect this hardware as much as possible.
It creates one Dask worker process per GPU, and assigns each worker
process the correct CPU cores and Network interface cards to
maximize performance.
That being said, things aren't perfect. Today a DGX has very high
performance between certain sets of GPUs and not others. A Dask DGX
cluster that uses only certain tightly coupled parts of the computer
will have significantly higher bandwidth than a deployment on the
entire thing.
Parameters
----------
interface: str
The interface prefix for the infiniband networking cards. This is
often "ib"` or "bond". We will add the numeric suffix 0,1,2,3 as
appropriate. Defaults to "ib".
dashboard_address: str
The address for the scheduler dashboard. Defaults to ":8787".
CUDA_VISIBLE_DEVICES: str
String like ``"0,1,2,3"`` or ``[0, 1, 2, 3]`` to restrict
activity to different GPUs
Examples
--------
>>> from dask_cuda import DGX
>>> from dask.distributed import Client
>>> cluster = DGX(interface='ib')
>>> client = Client(cluster)
"""
if CUDA_VISIBLE_DEVICES is None:
CUDA_VISIBLE_DEVICES = os.environ.get("CUDA_VISIBLE_DEVICES", "0,1,2,3,4,5,6,7")
if isinstance(CUDA_VISIBLE_DEVICES, str):
CUDA_VISIBLE_DEVICES = CUDA_VISIBLE_DEVICES.split(",")
CUDA_VISIBLE_DEVICES = list(map(int, CUDA_VISIBLE_DEVICES))
memory_limit = TOTAL_MEMORY / 8
spec = {
i: {
"cls": Nanny,
"options": {
"env": {
"CUDA_VISIBLE_DEVICES": cuda_visible_devices(
ii, CUDA_VISIBLE_DEVICES
),
"UCX_TLS": "rc,cuda_copy,cuda_ipc",
},
"interface": interface + str(i // 2),
"protocol": "ucx",
"ncores": threads_per_worker,
"data": dict,
"preload": ["dask_cuda.initialize_context"],
"dashboard_address": ":0",
"plugins": [CPUAffinity(affinity[i])],
"silence_logs": silence_logs,
"memory_limit": memory_limit,
},
}
for ii, i in enumerate(CUDA_VISIBLE_DEVICES)
}
scheduler = {
"cls": Scheduler,
"options": {
"interface": interface + str(CUDA_VISIBLE_DEVICES[0] // 2),
"protocol": "ucx",
"dashboard_address": dashboard_address,
},
}
return SpecCluster(
workers=spec,
scheduler=scheduler,
silence_logs=silence_logs,
**kwargs
)
However, we never got the NVLink structure down. The Dask scheduler currently still assumes uniform bandwidths between workers. We’ve started to make small steps towards changing this, but we’re not there yet (this will be useful as well for people that want to think about in-rack or cross-data-center deployments).
As usual, in solving a highly specific problem, we were able to solve a number of lingering general features, which then made our specific problem easy to write down.
Future Work
There has been significant effort over the last few months make everything above work. In particular we …
- Modified UCX to support client-server workloads
- Wrapped UCX with UCX-Py and design a Python async-await friendly interface
- Wrapped UCX-Py with Dask
- Hooked everything together to make generic workloads function well
The result is quite nice, especially for more communication heavy workloads. However there is still plenty to do. This section details what we’re thinking about now to continue this work.
-
Routing within complex networks: If you restrict yourself to four of the eight GPUs in a DGX, you can get 5-12 GB/s between pairs of GPUs. For some workloads this can be significant. It makes the system feel much more like a single unit than a bunch of isolated machines.
However we still can’t get great performance across the whole DGX because there are many GPU-pairs that are not connected by NVLink, and so we get 10x slower speeds. These dominate communication costs if you naively try to use the full DGX.
This might be solved either by:
- Teaching Dask to avoid these communications
- Teaching UCX to route communications like these through a chain of multiple NVLink connections
- Avoiding complex networks altogether. Newer systems like the DGX-2 use NVSwitch, which provides uniform connectivity, with each GPU connected to every other GPU.
Edit: I’ve since learned that UCX should be able to handle this. We should still get PCIe speeds (around 4-7 GB/s) even when we don’t have NVLink once an upstream bug gets fixed. Hooray!
-
CPU: We can get 1-2 GB/s across InfiniBand, which isn’t bad, but also wasn’t the full 5-8 GB/s that we were hoping for. This deserves more serious profiling to determine what is going wrong. The current guess is that this has to do with memory allocations.
In [1]: %time _ = b'0' * 1000000000 # 1 GB CPU times: user 248 ms, sys: 223 ms, total: 472 ms Wall time: 470 ms # <<----- Around 2 GB/s. Slower than I expectedProbably we’re just doing something dumb here.
-
Package UCX: Currently I’m building the UCX and UCX-Py libraries from source (see appendix below for instructions). Ideally these would become conda packages. John Kirkham (Conda Forge, NVIDIA, Dask) is taking a look at this along with the UCX developers from Mellanox.
See ucx-py #65 for more information.
-
Learn Heterogeneous Bandwidths: In order to make good scheduling decisions Dask needs to estimate how long it will take to move data between machines. This question is now becoming much more complex, and depends on both the source and destination machines (the network topology) the data type (NumPy array, GPU array, Pandas Dataframe with text) and more. In complex situations our bandwidths can span a 100x range (100 MB/s to 10 GB/s).
Dask will have to develop more complex models for bandwidth, and learn these over time.
See dask/distributed #2743 for more information.
-
Support other GPU libraries: To send GPU data around we need to teach Dask how to serialize Python objects into GPU buffers. There is code in the dask/distributed repository to do this for Numba, CuPy, and RAPIDS cuDF objects, but we’ve really only tested CuPy seriously. We should expand this by some of the following steps:
-
Try a distributed Dask cuDF join computation
See dask/distributed #2746 for initial work here.
-
Teach Dask to serialize array GPU libraries, like PyTorch and TensorFlow, or possibly anything that supports the
__cuda_array_interface__protocol.
-
-
Track down communication failures: We still occasionally get unexplained communication failures. We should stress test this system to discover rough corners.
-
TCP: Groups with high performing TCP networks can’t yet make use of UCX+Dask (though they can use either one individually).
Currently using UCX in a client-server mode as we’re doing with Dask requires access to RDMA libraries, which are often not found on systems without networking systems like InfiniBand. This means that groups with high performing TCP networks can’t make use of UCX+Dask.
This is in progress at openucx/ucx #3570
-
Commodity Hardware: Currently this code is only really useful on high performance Linux systems that have InfiniBand or NVLink. However, it would be nice to also use this on more commodity systems, including personal laptop computers using TCP and shared memory.
Currently Dask uses TCP for inter-process communication on a single machine. Using UCX on a personal computer would give us access to shared memory speeds, which tend to be an order of magnitude faster.
See openucx/ucx #3663 for more information.
-
Tune Performance: The 5-10 GB/s bandwidths that we see with NVLink today are sub-optimal. With UCX-Py alone we’re able to get something like 15 GB/s on large message tranfers. We should benchmark and tune our implementation to see what is taking up the extra time. Until things work more robustly though, this is a secondary priority.
Appendix: Setup
Performing these experiments depends currently on development branches in a few repositories. This section includes my current setup.
Create Conda Environment
conda create -n ucx python=3.7 libtool cmake automake autoconf cython bokeh pytest pkg-config ipython dask numba -y
Note: for some reason using conda-forge makes the autogen step below fail.
Set up UCX
# Clone UCX repository and get branch
git clone https://github.com/openucx/ucx
cd ucx
git remote add Akshay-Venkatesh [email protected]:Akshay-Venkatesh/ucx.git
git remote update Akshay-Venkatesh
git checkout ucx-cuda
# Build
git clean -xfd
export CUDA_HOME=/usr/local/cuda-9.2/
./autogen.sh
mkdir build
cd build
../configure --prefix=$CONDA_PREFIX --enable-debug --with-cuda=$CUDA_HOME --enable-mt --disable-cma CPPFLAGS="-I//usr/local/cuda-9.2/include"
make -j install
# Verify
ucx_info -d
which ucx_info # verify that this is in the conda environment
# Verify that we see NVLink speeds
ucx_perftest -t tag_bw -m cuda -s 1048576 -n 1000 & ucx_perftest dgx15 -t tag_bw -m cuda -s 1048576 -n 1000
Set up UCX-Py
git clone [email protected]:rapidsai/ucx-py
cd ucx-py
export UCX_PATH=$CONDA_PREFIX
make install
Set up Dask
git clone [email protected]:dask/dask.git
cd dask
pip install -e .
cd ..
git clone [email protected]:dask/distributed.git
cd distributed
pip install -e .
cd ..
Optionally set up cupy
pip install cupy-cuda92==6
Optionally set up cudf
conda install -c rapidsai-nightly -c conda-forge -c numba cudf dask-cudf cudatoolkit=9.2
Optionally set up JupyterLab
conda install ipykernel jupyterlab nb_conda_kernels nodejs
For the Dask dashboard
pip install dask_labextension
jupyter labextension install dask-labextension
My Benchmark
I’ve been using the following benchmark to test communication. It allocates a chunked Dask array, and then adds it to its transpose, which forces a lot of communication, but not much computation.
from collections import defaultdict
import asyncio
import time
import numpy as np
from pprint import pprint
import cupy
import dask.array as da
from dask.distributed import Client, wait
from distributed.utils import format_time, format_bytes
async def f():
# Set up workers on the local machine
async with DGX(asynchronous=True, silence_logs=True) as cluster:
async with Client(cluster, asynchronous=True) as client:
# Create a simple random array
rs = da.random.RandomState(RandomState=cupy.random.RandomState)
x = rs.random((40000, 40000), chunks='128 MiB').persist()
print(x.npartitions, 'chunks')
await wait(x)
# Add X to its transpose, forcing computation
y = (x + x.T).sum()
result = await client.compute(y)
# Collect, aggregate, and print peer-to-peer bandwidths
incoming_logs = await client.run(lambda dask_worker: dask_worker.incoming_transfer_log)
bandwidths = defaultdict(list)
for k, L in incoming_logs.items():
for d in L:
if d['total'] > 1_000_000:
bandwidths[k, d['who']].append(d['bandwidth'])
bandwidths = {
(cluster.scheduler.workers[w1].name,
cluster.scheduler.workers[w2].name): [format_bytes(x) + '/s' for x in np.quantile(v, [0.25, 0.50, 0.75])]
for (w1, w2), v in bandwidths.items()
}
pprint(bandwidths)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(f())
Note: most of this example is just getting back diagnostics, which can be easily ignored. Also, you can drop the async/await code if you like. I think that there should probably be more examples in the world using Dask with async/await syntax, so I decided to leave it in.
blog comments powered by Disqus