Refactor Documentation
By Matthew Rocklin and Tom Augspurger
This work is supported by Anaconda Inc
Summary
We recently changed how we organize and connect Dask’s documentation. Our approach may prove useful for other umbrella projects that spread documentation across many different builds and sites.
Dask splits documentation into many pages
Dask’s documentation is split into several different websites, each managed by a different team for a different sub-project:
- dask.pydata.org : Main site
- distributed.readthedocs.org : Distributed scheduler
- dask-ml.readthedocs.io : Dask for machine learning
- dask-kubernetes.readthedocs.io : Dask on Kubernetes
- dask-jobqueue.readthedocs.io : Dask on HPC systems
- dask-yarn.readthedocs.io : Dask on Hadoop systems
- dask-examples.readthedocs.io : Examples that use Dask
- matthewrocklin.com/blog, jcrist.github.io, tomaugspurger.github.io, martindurant.github.io/blog : Developers’ personal blogs
This split in documentation matches the split in development teams. Each of sub-project’s team manages its own docs in its own way. They release at their own pace and make their own decisions about technology. This makes it much more likely that developers maintain the documentation as they develop and change software libraries.
We make it easy to write documentation. This choice causes many different documentation systems to emerge.
This approach is common. A web search for Jupyter Documentation yields the following list:
- jupyter.readthedocs.io/en/latest/
- jupyter-notebook.readthedocs.io/en/stable/
- jupyter.org/
- jupyterhub.readthedocs.io/en/stable/
- nteract.io/
- ipython.org/
Different teams developing semi-independently create different web pages. This is inevitable. Asking a large distributed team to coordinate on a single cohesive website adds substantial friction, which results in worse documentation coverage.
Problem
However, while using separate websites results in excellent coverage, it also fragments the documentation. This makes it harder for users to smoothly navigate between sites and discover appropriate content.
Monolithic documentation is good for readers, modular documentation is good for writers.
Our Solutions
Over the last month we took steps to connect our documentation and make it more cohesive, while still enabling independent development. This post outlines the following steps:
- Organize under a single domain, dask.org
- Develop a sphinx template project for uniform style
- Include a cross-project navbar in addition to the within-project table-of-contents
We did some other things along the way that we find useful, but are probably more specific to just Dask.
- We moved this blog to blog.dask.org
- We improved our example notebooks to host both a static site and also a live Binder
1: Organize under a single domains, Dask.org
Previously we had some documentation under readthedocs, some under the dask.pydata.org subdomain (thanks NumFOCUS!) and some pages on personal websites, like matthewrocklin.com/blog.
While looking for a new dask domain to host all of our content we noticed that dask.org redirected to anaconda.org, and were pleased to learn that someone at Anaconda Inc had the foresight to register the domain early on.
Anaconda was happy to transfer ownership of the domain to NumFOCUS, who helps us to maintain it now. Now all of our documentation is available under that single domain as subdomains:
- dask.org
- docs.dask.org
- distributed.dask.org
- ml.dask.org
- kubernetes.dask.org
- yarn.dask.org
- jobqueue.dask.org
- examples.dask.org
- stories.dask.org
- blog.dask.org
This uniformity means that the thing you want is probably at that-thing.dask.org, which is a bit easier to guess than otherwise.
Many thanks to Andy Terrel and Tom Augspurger for managing this move, and to Anaconda for generously donating the domain.
2: Cross-project Navigation Bar
We wanted a way for readers to quickly discover the other sites that were available to them. All of our sites have side-navigation-bars to help readers navigate within a particular site, but now they also have a top-navigation-bar to help them navigate between projects.
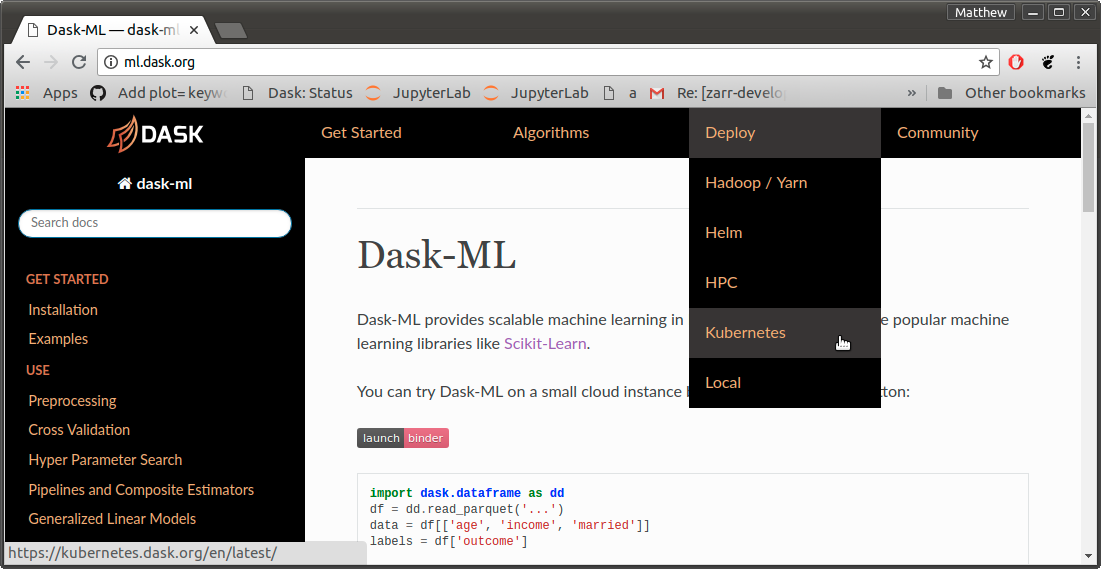
This navigation bar is managed independently from all of the documentation projects at our new Sphinx theme.
3: Dask Sphinx Theme
To give a uniform sense of style we developed our own Sphinx HTML theme. This inherits from ReadTheDocs’ theme, but with changed styling to match Dask color and visual style. We publish this theme as a package on PyPI that all of our projects’ Sphinx builds can import and use if they want. We can change style in this one package and publish to PyPI and all of the projects will pick up those changes on their next build without having to copy stylesheets around to different repositories.
This allows several different projects to evolve content (which they care about) and build process separately from style (which they typically don’t care as much about). We have a single style sheet that gets used everywhere easily.
4: Move Dask Blogging to blog.dask.org
Previously most announcements about Dask were written and published from one of the maintainers’ personal blogs. This split information about the project and made it hard for people to discover good content. There also wasn’t a good way for a community member to suggest a blog for distribution to the general community, other than by starting their own.
Now we have an official blog at blog.dask.org which
serves files submitted to
github.com/dask/dask-blog. These posts
are simple markdown files that should be easy for people to generate. For
example the source for this post is available at
github.com/dask/dask-blog/blob/gh-pages/_posts/2018-09-27-docs-refactor.md
We encourage community members to share posts about work they’ve done with Dask by submitting pull requests to that repository.
5: Host Examples as both static HTML and live Binder sessions
The Dask community maintains a set of example notebooks that show people how to use Dask in a variety of ways. These notebooks live at github.com/dask/dask-examples and are easy for users to download and run.
To get more value from these notebooks we now expose them in two additional ways:
-
As static HTML at examples.dask.org, rendered with the nbsphinx plugin.
Seeing them statically rendered and being able to quickly navigate between them really increases the pleasure of exploring them. We hope that this encourages users to explore more broadly.
-
As live-runnable notebooks on the cloud using mybinder.org. You can play with any of these notebooks by clicking on this button:
 .
.This allows people to explore more deeply. Also, because we’ve connected up the Dask JupyterLab extension to this environment, users get an immediate instinctual experience of what parallel computing feels like (if you haven’t used the dask dashboard during computation you really should give that link a try).
Now that these examples get much more exposure we hope that this encourages community members to submit new examples. We hope that by providing infrastructure more content creators will come as well.
We also encourage other projects to take a look at what we’ve done in github.com/dask/dask-examples. We think that this model might be broadly useful across other projects.
Conclusion
Thank you for reading. We hope that this post pushes readers to re-explore Dask’s documentation, and that it pushes developers to consider some of the approaches above for their own projects.
blog comments powered by Disqus