Dask Release 0.15.3
This work is supported by Anaconda Inc. and the Data Driven Discovery Initiative from the Moore Foundation.
I’m pleased to announce the release of Dask version 0.15.3. This release contains stability enhancements and bug fixes. This blogpost outlines notable changes since the 0.15.2 release on August 30th.
You can conda install Dask:
conda install -c conda-forge dask
or pip install from PyPI
pip install dask[complete] --upgrade
Conda packages are available both on conda-forge channels. They will be on defaults in a few days.
Full changelogs are available here:
Some notable changes follow.
Masked Arrays
Dask.array now supports masked arrays similar to NumPy.
In [1]: import dask.array as da
In [2]: x = da.arange(10, chunks=(5,))
In [3]: mask = x % 2 == 0
In [4]: m = da.ma.masked_array(x, mask)
In [5]: m
Out[5]: dask.array<masked_array, shape=(10,), dtype=int64, chunksize=(5,)>
In [6]: m.compute()
Out[6]:
masked_array(data = [-- 1 -- 3 -- 5 -- 7 -- 9],
mask = [ True False True False True False True False True False],
fill_value = 999999)
This work was primarily done by Jim Crist and partially funded by the UK Met office in support of the Iris project.
Constants in atop
Dask.array experts will be familiar with the atop
function, which powers a non-trivial amount of dask.array and is commonly used by people building custom algorithms. This function now supports constants when the index given is None.
atop(func, 'ijk', x, 'ik', y, 'kj', CONSTANT, None)
Memory management for workers
Dask workers spill excess data to disk when they reach 60% of their alloted memory limit. Previously we only measured memory use by adding up the memory use of every piece of data produce by the worker. This could fail under a few situations
- Our per-data estiamtes were faulty
- User code consumed a large amount of memory without our tracking it
To compensate we now also periodically check the memory use of the worker using system utilities with the psutil module. We dump data to disk if the process rises about 70% use, stop running new tasks if it rises above 80%, and restart the worker if it rises above 95% (assuming that the worker has a nanny process).
Breaking Change: Previously the --memory-limit keyword to the
dask-worker process specified the 60% “start pushing to disk” limit. So if
you had 100GB of RAM then you previously might have started a dask-worker as
follows:
dask-worker ... --memory-limit 60e9 # before specify 60% target
And the worker would start pushing to disk once it had 60GB of data in memory. However, now we are changing this meaning to be the full amount of memory given to the process.
dask-worker ... --memory-limit 100e9A # now specify 100% target
Of course, you don’t have to sepcify this limit (many don’t). It will be chosen for you automatically. If you’ve never cared about this then you shouldn’t start caring now.
More about memory management here: http://distributed.readthedocs.io/en/latest/worker.html?highlight=memory-limit#memory-management
Statistical Profiling
Workers now poll their worker threads every 10ms and keep a running count of which functions are being used. This information is available on the diagnostic dashboard as a new “Profile” page. It provides information that is orthogonal, and generally more detailed than the typical task-stream plot.
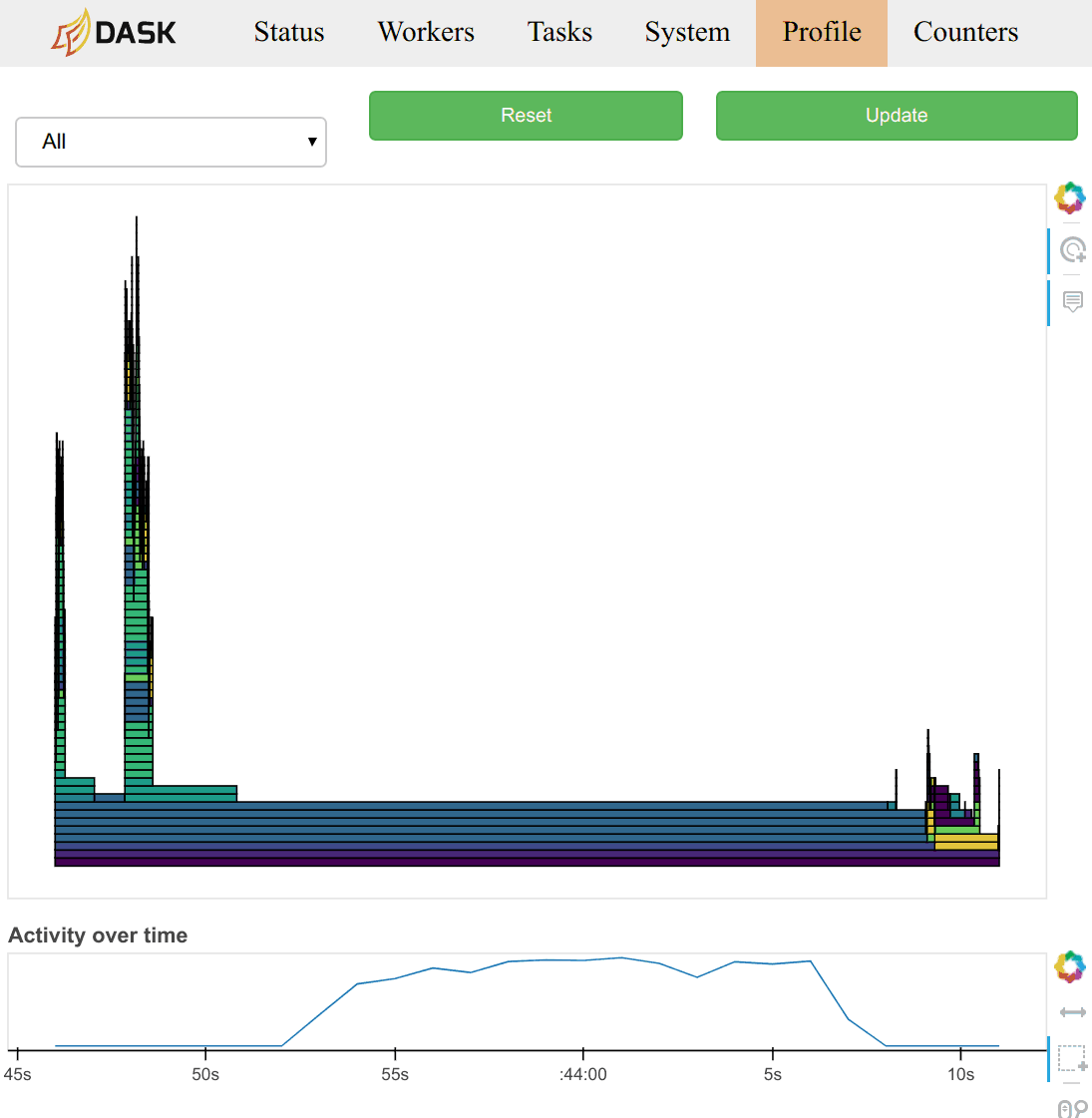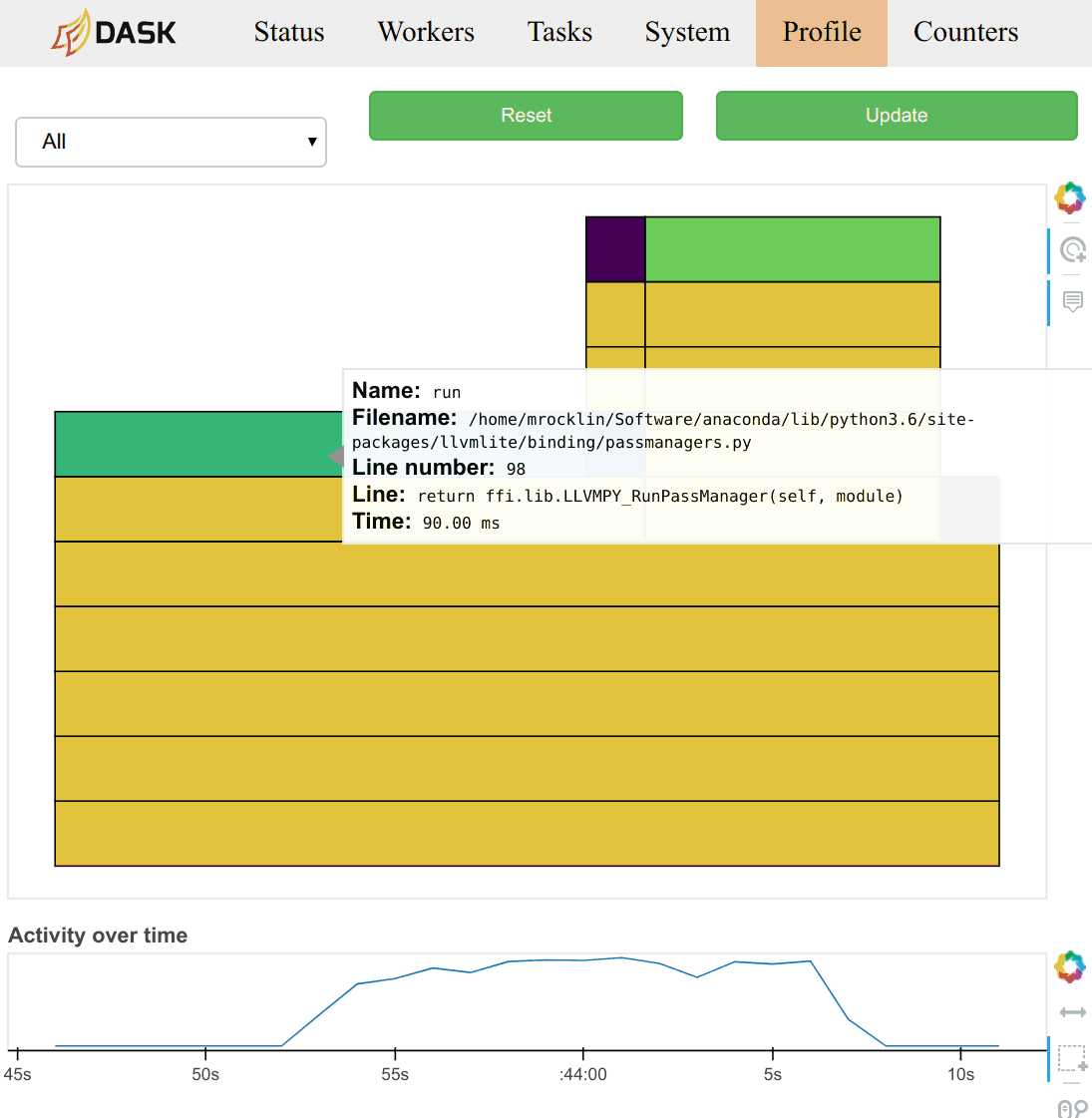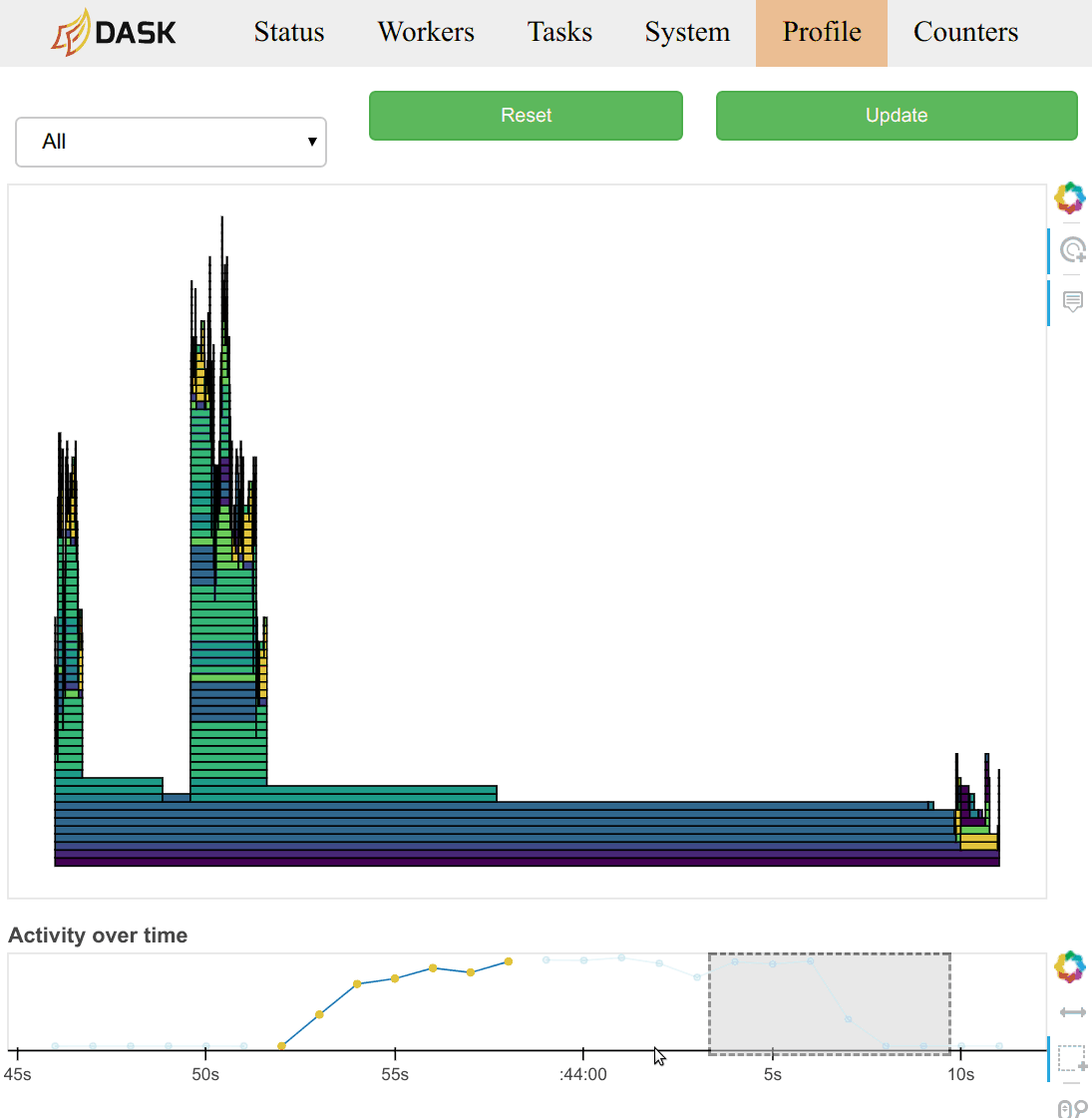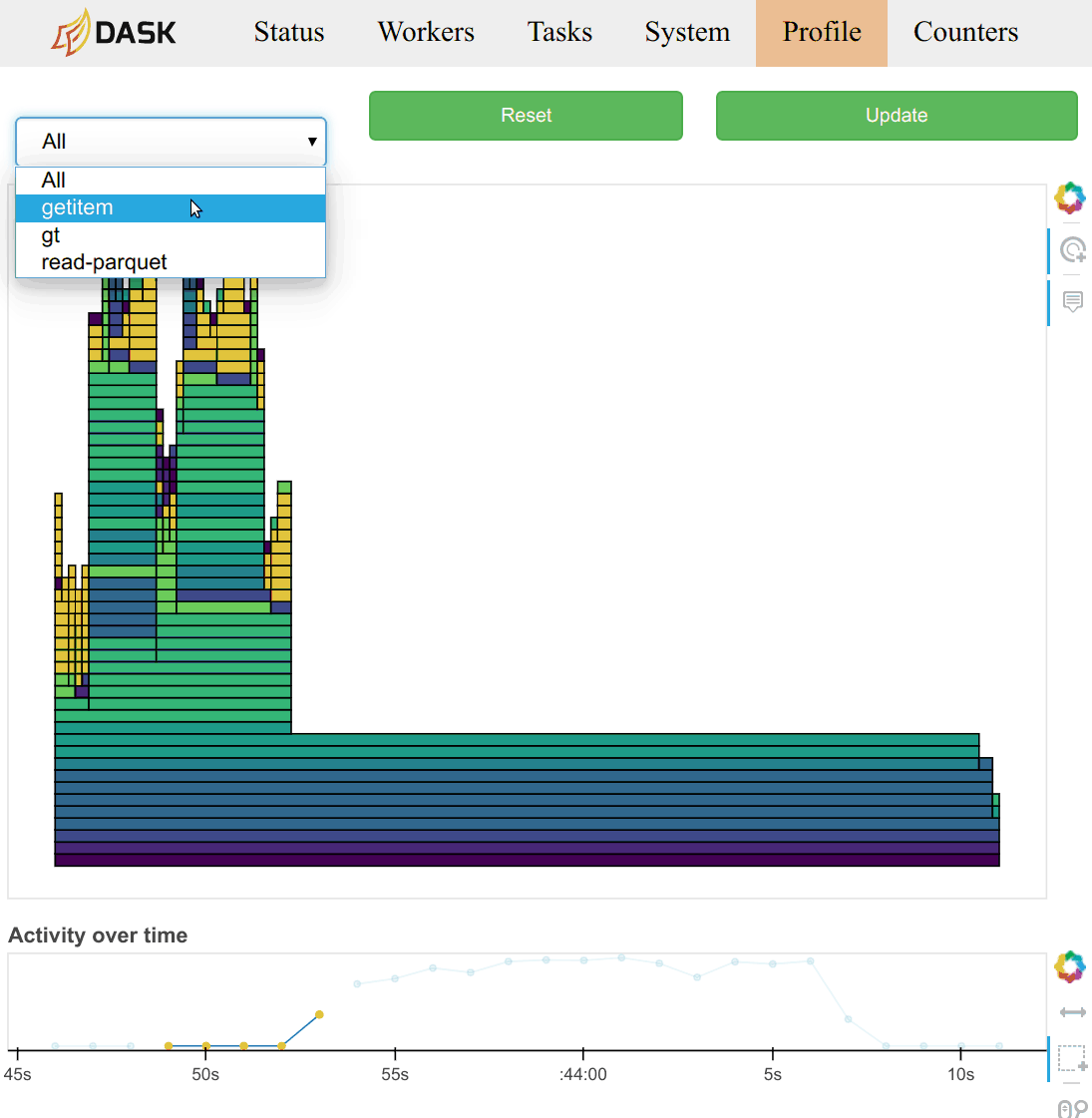
These plots are available on each worker, and an aggregated view is available on the scheduler. The timeseries on the bottom allows you to select time windows of your computation to restrict the parallel profile.
More information about diagnosing performance available here: http://distributed.readthedocs.io/en/latest/diagnosing-performance.html
Acknowledgements
The following people contributed to the dask/dask repository since the 0.15.2 release on August 30th
- Adonis
- Christopher Prohm
- Danilo Horta
- jakirkham
- Jim Crist
- Jon Mease
- jschendel
- Keisuke Fujii
- Martin Durant
- Matthew Rocklin
- Tom Augspurger
- Will Warner
The following people contributed to the dask/distributed repository since the 1.18.3 release on September 2nd:
- Casey Law
- Edrian Irizarry
- Matthew Rocklin
- rbubley
- Tom Augspurger
- ywangd
blog comments powered by Disqus