Dask Development Log
This work is supported by Continuum Analytics the XDATA Program and the Data Driven Discovery Initiative from the Moore Foundation
To increase transparency I’m blogging weekly about the work done on Dask and related projects during the previous week. This log covers work done between 2016-12-11 and 2016-12-18. Nothing here is ready for production. This blogpost is written in haste, so refined polish should not be expected.
Themes of last week:
- Cleanup of load balancing
- Found cause of worker lag
- Initial Spark/Dask Dataframe comparisons
- Benchmarks with asv
Load Balancing Cleanup
The last two weeks saw several disruptive changes to the scheduler and workers. This resulted in an overall performance degradation on messy workloads when compared to the most recent release, which stopped bleeding-edge users from using recent dev builds. This has been resolved, and bleeding-edge git-master is back up to the old speed and then some.
As a visual aid, this is what bad (or in this case random) load balancing looks like:
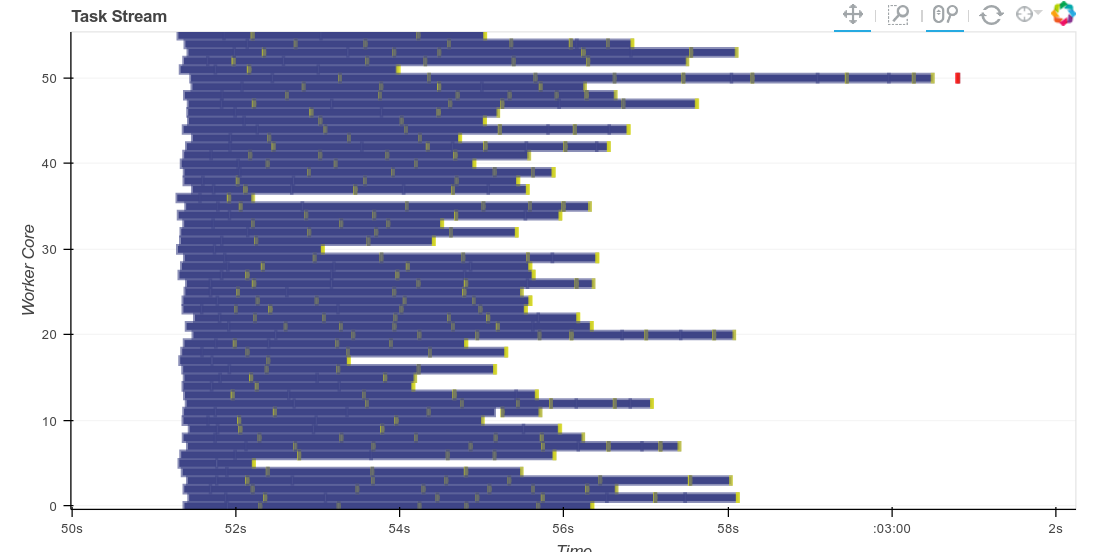
Identified and removed worker lag
For a while there have been significant gaps of 100ms or more between successive tasks in workers, especially when using Pandas. This was particularly odd because the workers had lots of backed up work to keep them busy (thanks to the nice load balancing from before). The culprit here was the calculation of the size of the intermediate on object dtype dataframes.
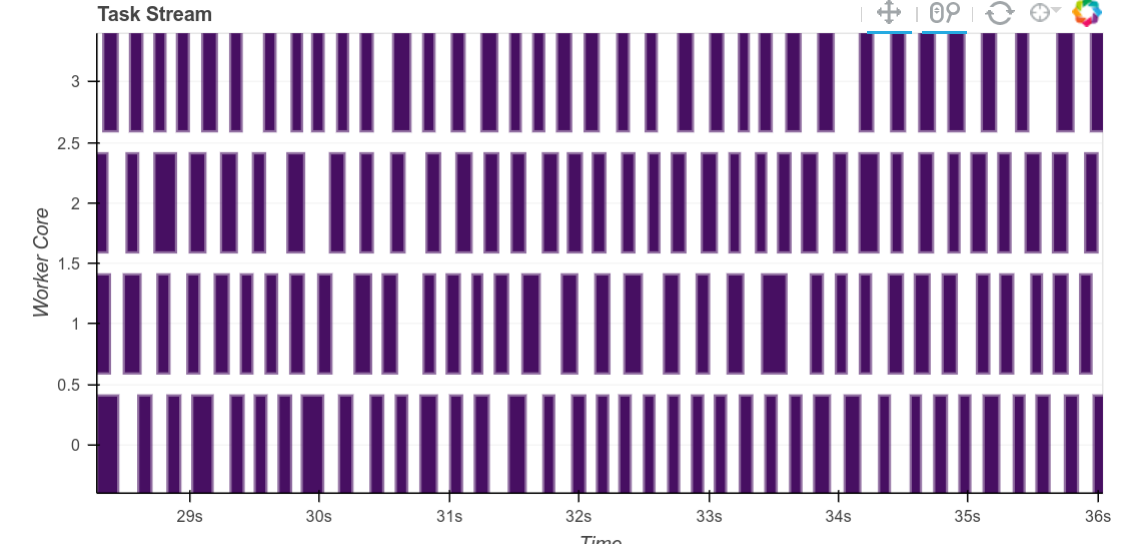
Explaining this in greater depth, recall that to schedule intelligently, the workers calculate the size in bytes of every intermediate result they produce. Often this is quite fast, for example for numpy arrays we can just multiply the number of elements by the dtype itemsize. However for object dtype arrays or dataframes (which are commonly used for text) it can take a long while to calculate an accurate result here. Now we no longer calculuate an accurate result, but instead take a fairly pessimistic guess. The gaps between tasks shrink considerably.
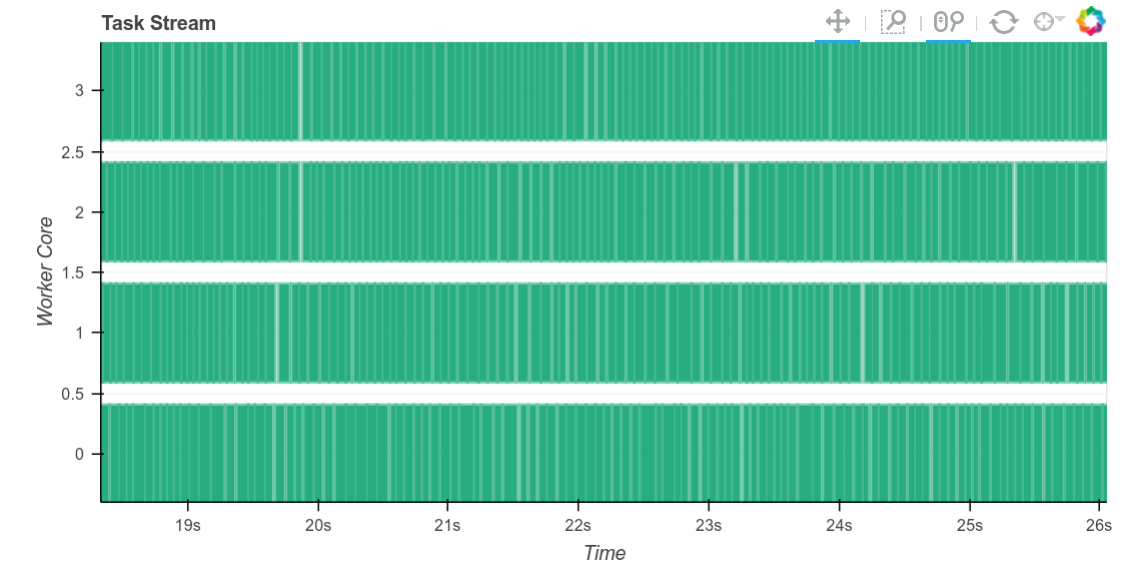
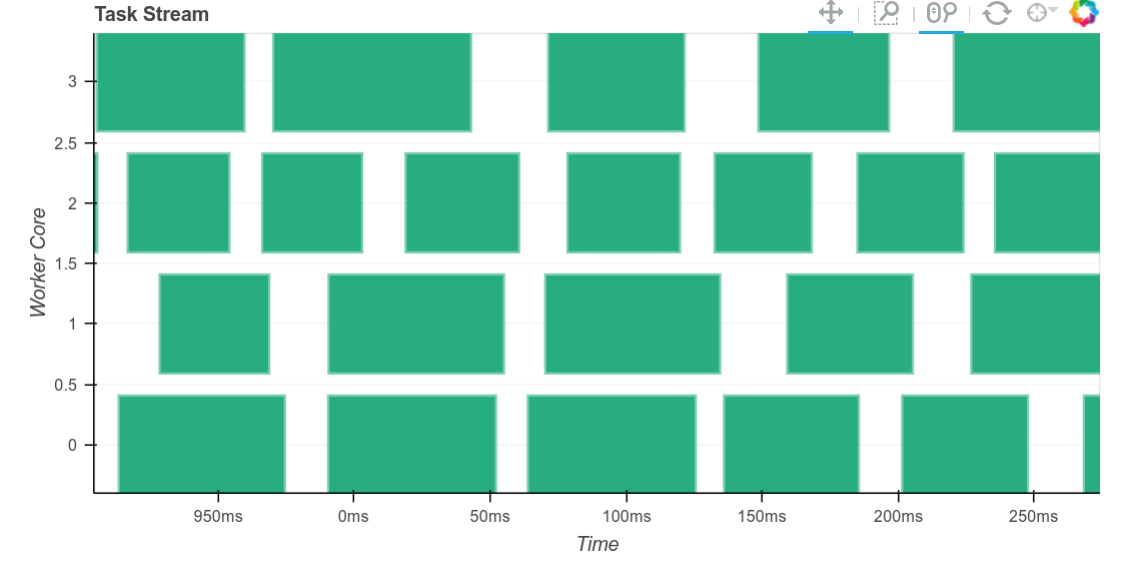
Although there is still a significant bit of lag around 10ms long between tasks on these workloads (see zoomed version on the right). On other workloads we’re able to get inter-task lag down to the tens of microseconds scale. While 10ms may not sound like a long time, when we perform very many very short tasks this can quickly become a bottleneck.
Anyway, this change reduced shuffle overhead by a factor of two. Things are starting to look pretty snappy for many-small-task workloads.
Initial Spark/Dask Dataframe Comparisons
I would like to run a small benchmark comparing Dask and Spark DataFrames. I spent a bit of the last couple of days using Spark locally on the NYC Taxi data and futzing with cluster deployment tools to set up Spark clusters on EC2 for basic benchmarking. I ran across flintrock, which has been highly recommended to me a few times.
I’ve been thinking about how to do benchmarks in an unbiased way. Comparative benchmarks are useful to have around to motivate projects to grow and learn from each other. However in today’s climate where open source software developers have a vested interest, benchmarks often focus on a projects’ strengths and hide their deficiencies. Even with the best of intentions and practices, a developer is likely to correct for deficiencies on the fly. They’re much more able to do this for their own project than for others’. Benchmarks end up looking more like sales documents than trustworthy research.
My tentative plan is to reach out to a few Spark devs and see if we can collaborate on a problem set and hardware before running computations and comparing results.
Benchmarks with airspeed velocity
Rich Postelnik is building on work from Tom Augspurger to build out benchmarks for Dask using airspeed velocity at dask-benchmarks. Building out benchmarks is a great way to get involved if anyone is interested.
Pre-pre-release
I intend to publish a pre-release for a 0.X.0 version bump of dask/dask and dask/distributed sometime next week.
blog comments powered by Disqus