State of Dask
This work is supported by Continuum Analytics and the XDATA Program as part of the Blaze Project
tl;dr We lay out the pieces of Dask, a system for parallel computing
Introduction
Dask started five months ago as a parallel on-disk array; it has since broadened out. I’ve enjoyed writing about its development tremendously. With the recent 0.5.0 release I decided to take a moment to give an overview of dask’s various pieces, their state, and current development.
Collections, graphs, and schedulers
Dask modules can be separated as follows:
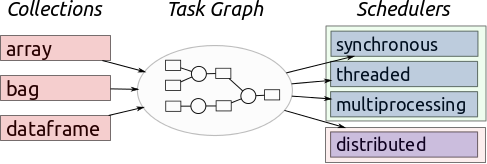
On the left there are collections like arrays, bags, and dataframes. These copy APIs for NumPy, PyToolz, and Pandas respectively and are aimed towards data science users, allowing them to interact with larger datasets. Operations on these dask collections produce task graphs which are recipes to compute the desired result using many smaller computations that each fit in memory. For example if we want to sum a trillion numbers then we might break the numbers into million element chunks, sum those, and then sum the sums. A previously impossible task becomes a million and one easy ones.
On the right there are schedulers. Schedulers execute task graphs in different situations, usually in parallel. Notably there are a few schedulers for a single machine, and a new prototype for a distributed scheduler.
In the center is the directed acyclic graph. This graph serves as glue between collections and schedulers. The dask graph format is simple and doesn’t include any dask classes; it’s just functions, dicts, and tuples and so is easy to build on and low-tech enough to understand immediately. This separation is very useful to dask during development; improvements to one side immediately affect the other and new developers have had surprisingly little trouble. Also developers from a variety of backgrounds have been able to come up to speed in about an hour.
This separation is useful to other projects too. Directed acyclic graphs are popular today in many domains. By exposing dask’s schedulers publicly, other projects can bypass dask collections and go straight for the execution engine.
A flattering quote from a github issue:
dask has been very helpful so far, as it allowed me to skip implementing all of the usual graph operations. Especially doing the asynchronous execution properly would have been a lot of work.
Who uses dask?
Dask developers work closely with a few really amazing users:
-
Stephan Hoyer at Climate Corp has integrated
dask.arrayintoxraya library to manage large volumes of meteorlogical data (and other labeled arrays.) -
Scikit image now includes an apply_parallel operation (github PR) that uses dask.array to parallelize image processing routines. (work by Blake Griffith)
-
Mariano Tepper a postdoc at Duke, uses dask in his research on matrix factorizations. Mariano is also the primary author of the
dask.array.linalgmodule, which includes efficient and stable QR and SVD for tall and skinny matrices. See Mariano’s paper on arXiv. -
Finally I personally use dask on daily work related to the XData project. This tends to drive some of the newer features.
A few other groups pop up on github from time to time; I’d love to know more detail about how people use dask.
What works and what doesn’t
Dask is modular. Each of the collections and each of the schedulers are effectively separate projects. These subprojects are at different states of development. Knowing the stability of each subproject can help you to determine how you use and depend on dask.
Dask.array and dask.threaded work well, are stable, and see constant use.
They receive relatively minor bug reports which are dealt with swiftly.
Dask.bag and dask.multiprocessing undergo more API churn but are mostly
ready for public use with a couple of caveats. Neither dask.dataframe nor
dask.distributed are ready for public use; they undergo significant API churn
and have known errors.
Current work
The current state of development as I see it is as follows:
- Dask.bag and dask.dataframe are progressing nicely. My personal work
depends on these modules, so they see a lot of attention.
- At the moment I focus on grouping and join operations through fast shuffles; I hope to write about this problem soon.
- The Pandas API is large and complex. Reimplementing a subset of it in a blocked way is straightforward but also detailed and time consuming. This would be a great place for community contributions.
- Dask.distributed is new. It needs it tires kicked but it’s an exciting
development.
- For deployment we’re planning to bootstrap off of IPython parallel which already has decent coverage of many parallel job systems, (see #208 by Blake)
- Dask.array development these days focuses on outreach. We’ve found application domains where dask is very useful; we’d like to find more.
- The collections (Array, Bag, DataFrame) don’t cover all cases. I would like to start finding uses for the task schedulers in isolation. They serve as a release valve in complex situations.
More information
You can install dask with conda
conda install dask
or with pip
pip install dask
or
pip install dask[array]
or
pip install dask[bag]
You can read more about dask at the docs or github.
blog comments powered by Disqus