Dask Development Log
This work is supported by Continuum Analytics the XDATA Program and the Data Driven Discovery Initiative from the Moore Foundation
To increase transparency I’m blogging weekly about the work done on Dask and related projects during the previous week. This log covers work done between 2016-12-05 and 2016-12-12. Nothing here is stable or ready for production. This blogpost is written in haste, so refined polish should not be expected.
Themes of last week:
- Dask.array without known chunk sizes
- Import time
- Fastparquet blogpost and feedback
- Scheduler improvements for 1000+ worker clusters
- Channels and inter-client communication
- New dependencies?
Dask array without known chunk sizes
Dask arrays can now work even in situations where we don’t know the exact chunk size. This is particularly important because it allows us to convert dask.dataframes to dask.arrays in a standard analysis cycle that includes both data preparation and statistical or machine learning algorithms.
x = df.values
x = df.to_records()
This work was motivated by the work of Christopher White on building scalable solvers for problems like logistic regression and generalized linear models over at dask-glm.
As a pleasant side effect we can now also index dask.arrays with dask.arrays (a previous limitation)
x[x > 0]
and mutate dask.arrays in certain cases with setitem
x[x > 0] = 0
Both of which are frequntly requested.
However, there are still holes in this implementation and many operations (like slicing) generally don’t work on arrays without known chunk sizes. We’re increasing capability here but blurring the lines of what is possible and what is not possible, which used to be very clear.
Import time
Import times had been steadily climbing for a while, rising above one second at times. These were reduced by Antoine Pitrou down to a more reasonable 300ms.
FastParquet blogpost and feedback
Martin Durant has built a nice Python Parquet library here: http://fastparquet.readthedocs.io/en/latest/ and released a blogpost about it last week here: https://www.continuum.io/blog/developer-blog/introducing-fastparquet
Since then we’ve gotten some good feedback and error reports (non-string column names etc.) Martin has been optimizing performance and recently adding append support.
Scheduler optimizations for 1000+ worker clusters
The recent refactoring of the scheduler and worker exposed new opportunities for performance and for measurement. One of the 1000+ worker deployments here in NYC was kind enough to volunteer some compute time to run some experiments. It was very fun having all of the Dask/Bokeh dashboards up at once (there are now half a dozen of these things) giving live monitoring information on a thousand-worker deployment. It’s stunning how clearly performance issues present themselves when you have the right monitoring system.
Anyway, this lead to better sequentialization when handling messages, greatly reduced open file handle requirements, and the use of cytoolz over toolz in a few critical areas.
I intend to try this experiment again this week, now with new diagnostics. To aid in that we’ve made it very easy to turn timings and counters automatically into live Bokeh plots. It now takes literally one line of code to add a new plot to these pages (left: scheduler right: worker)
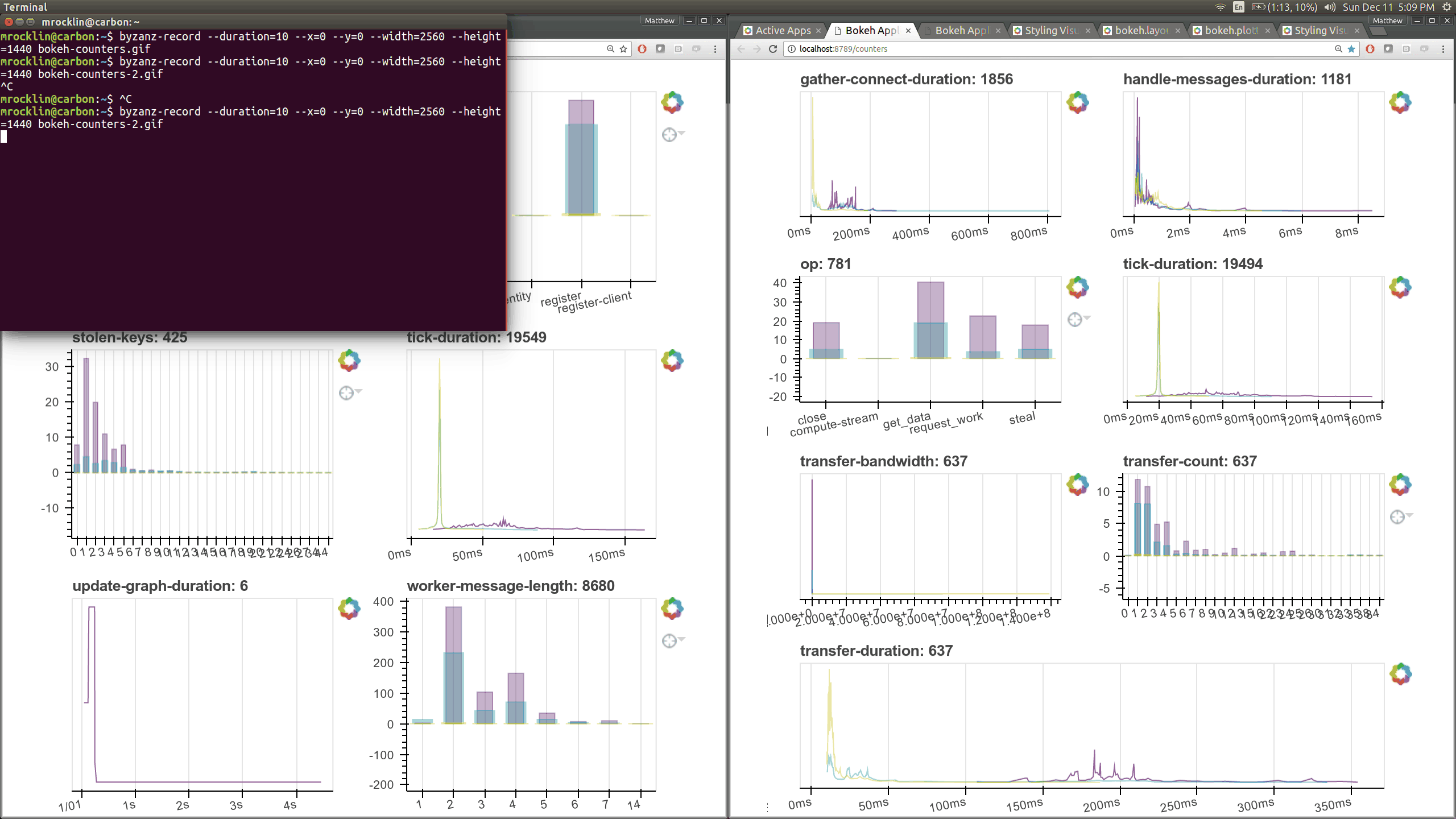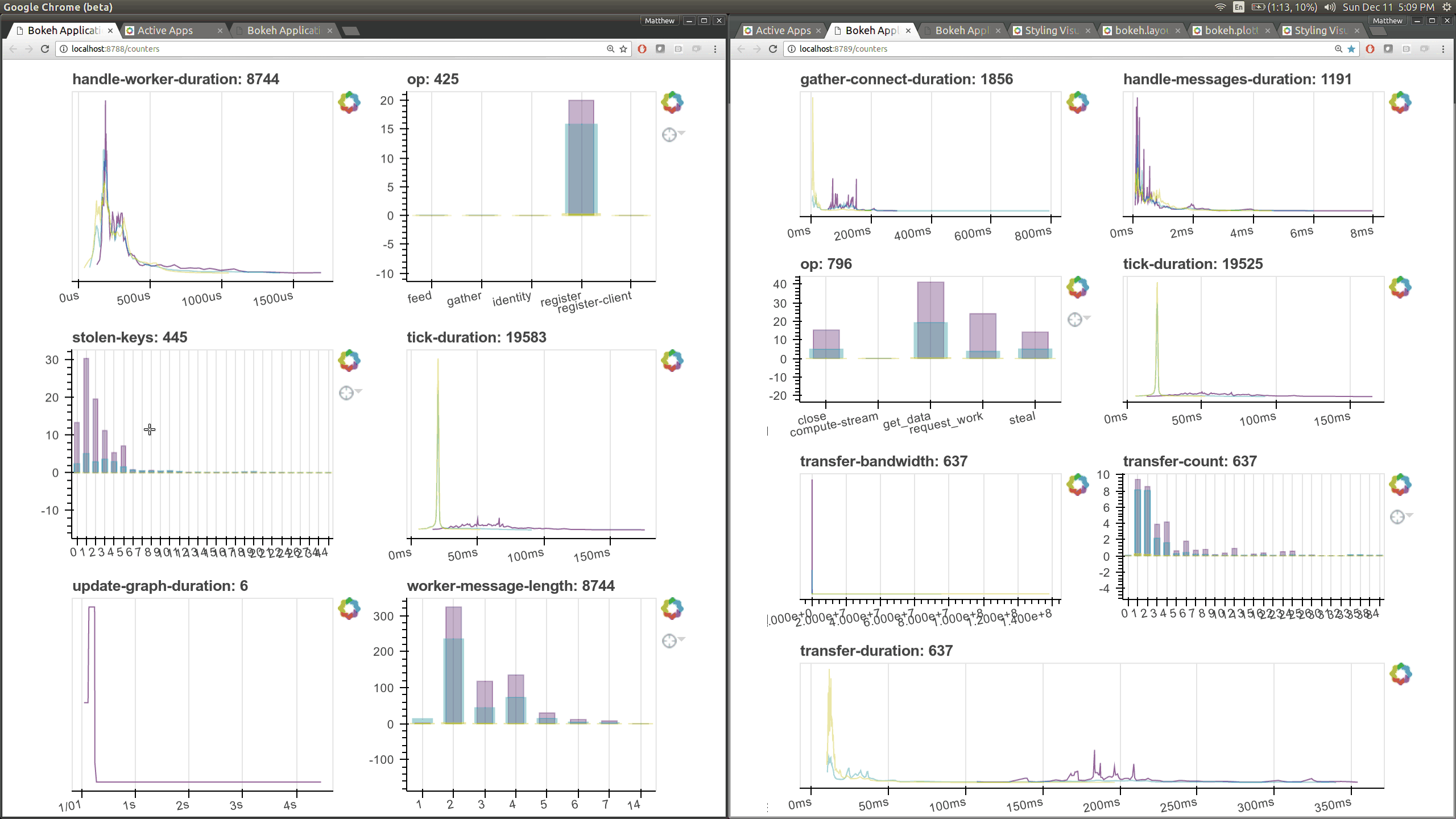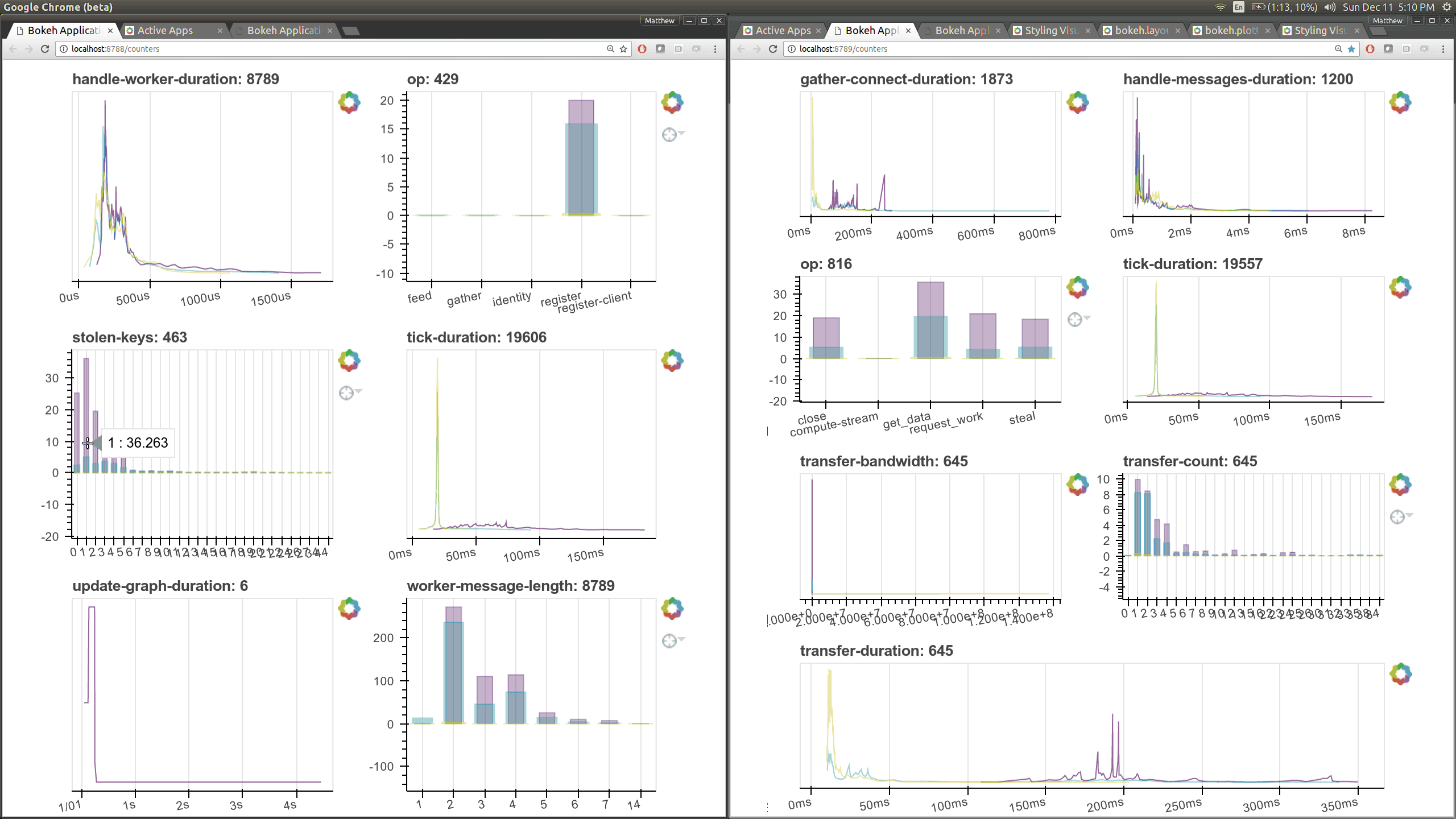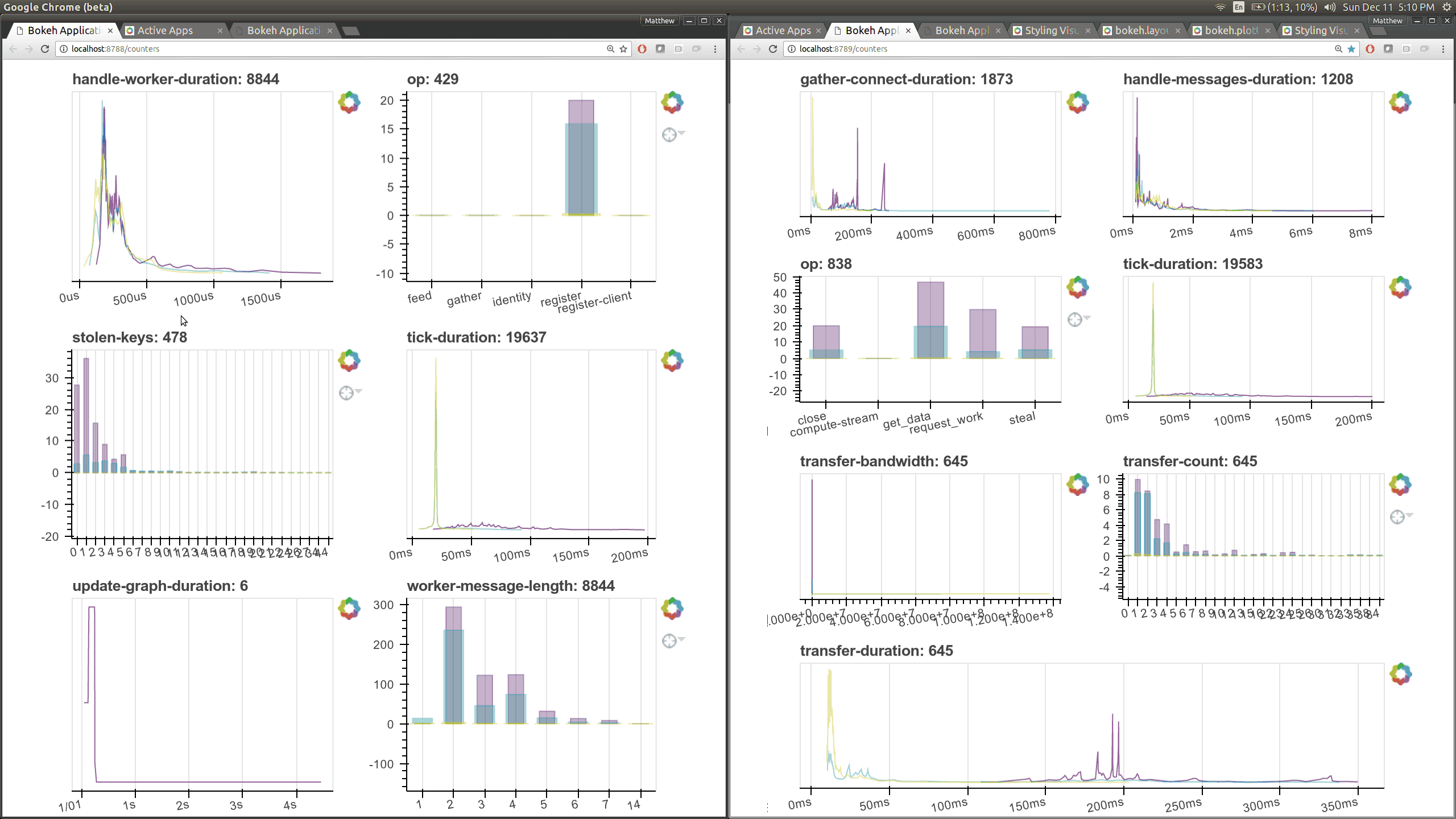
Already we can see that the time it takes to connect between workers is absurdly high in the 10ms to 100ms range, highlighting an important performance flaw.
This depends on an experimental project, crick, by Jim Crist that provides a fast T-Digest implemented in C (see also Ted Dunning’s implementation.
Channels and inter-worker communication
I’m starting to experiment with mechanisms for inter-client communication of futures. This enables both collaborative workflows (two researchers sharing the same cluster) and also complex workflows in which tasks start other tasks in a more streaming setting.
We added a simple mechanism to share a rolling buffer of futures between clients:
# Client 1
c = Client('scheduler:8786')
x = c.channel('x')
future = c.submit(inc, 1)
x.put(future)
# Client 1
c = Client('scheduler:8786')
x = c.channel('x')
future = next(iter(x))
Additionally, this relatively simple mechanism was built external to the scheduler and client, establishing a pattern we can repeat in the future for more complex inter-client communication systems. Generally I’m on the lookout for other ways to make the system more extensible. This range of extension requests for the scheduler is somewhat large these days and we’d like to find ways to keep these expansions maintainable going forward.
New dependency: Sorted collections
The scheduler is now using the sortedcollections module, which is based off
of sortedcontainers which is a pure-Python library offering sorted containers
SortedList, SortedSet, ValueSortedDict, etc. at C-extensions speeds.
So far I’m pretty sold on these libraries. I encourage other library maintainers to consider them.
- https://www.youtube.com/watch?v=7z2Ki44Vs4E
- http://www.grantjenks.com/docs/sortedcontainers/introduction.html
- http://www.grantjenks.com/docs/sortedcollections/
blog comments powered by Disqus